1/ Introduction : Pourquoi cartographier ?
- 1/A Les outils de collecte des données sur le web et les réseaux sociaux
- 1/B Les outils de représentation
- 1/C Introduction à la représentation cartographique : notions de base et vocabulaire
- 1/D L’interface de Gephi
2/ Quel(s) algorithme(s) pour quel(s) objectif(s) de représentation ?
- 2/A Mettre en avant des divisions entre différentes composantes de la cartographie
- 2/B Mettre en avant des complémentarités entre les différents éléments de la cartographie
- 2/C Mettre en avant une logique de classification des éléments du graphique
- 2/D Autres algorithmes
3/ Représenter les nœuds en fonction des différents degrés de centralité
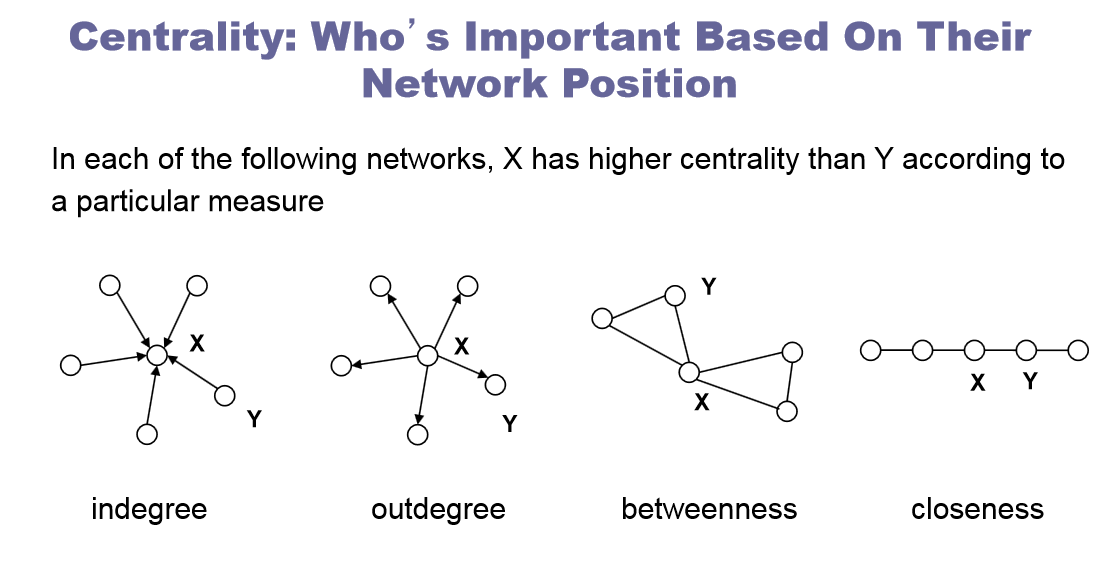
- 3/A Degree centrality = A combien de personnes un compte peut accéder directement ?
- 3/B Closeness centrality = En combien de temps un compte peut-il toucher l’ensemble du réseau ?
- 3/C Betweenness centrality (Entremise ?) = Quelle est la probabilité que cette personne soit l’itinéraire le plus direct entre deux personnes dans le réseau ?
- 3/D « Centralité Eigenvector » = A combien de personnes bien connectées ce compte est-il connecté ?
- 3/E Modularity class = Identifier les relations entre les nœuds et mettre en avant des communautés
- 3/F Aller plus loin dans l’analyse en combinant des filtres
4/ SIGMA : L’export analytique et esthétique
1/ Introduction : Pourquoi cartographier ?
La cartographie du web ou des réseaux sociaux s’appuie sur l’idée que les liens créés sur le web entre différents acteurs (sites web, comptes twitter…) peuvent être perçus comme des liens sociaux. D’un point de vue pratique, il s’agit de retracer dans un graphe le réseau créé par les liens hypertextes pour les sites web ou les liens entre les internautes lors d’une discussion sur les réseaux sociaux. La cartographie fait alors apparaître les différentes relations entre les comptes ou sites, le degré d’interaction, d’occurrence, le poids de chacune d’entre elles. La cartographie permet de faire émerger des territoires communautaires en ligne et d’en observer les dynamiques.
Objectifs et enjeux de la cartographie :
- Explorer les liens sociaux virtuels,
- Définir le rôle et l’importance de chaque acteur lors d’une discussion sur le web et les réseaux sociaux, au sein d’une ou plusieurs communautés,
- Détecter les acteurs et comptes influents,
- Appréhender les comportements d’une communauté en ligne,
- Anticiper les risques en fonction de l’agenda et des thématiques pouvant mobiliser,
- Gérer les risques et les attaques sur la réputation en ligne.
1/A Les outils de collecte des données sur le web et les réseaux sociaux
Pour les cartographies web :
- l’exploration, les outils les plus employés sont les crawlers. Un crawler est un logiciel qui permet de naviguer dans une série de pages web et de tracer tous leurs liens hypertexte. Les crawlers peuvent être automatiques ou, plus rarement, manuels. En outre, de nouvelles méthodologies ont été récemment développées pour explorer les données des réseaux sociaux en ligne. ➔
Extraction de données pour les réseaux sociaux :
- le modèle NodelX pour Microsoft Excel 2007, 2010 et 2013, permet la collecte rapide des données de médias sociaux via un ensemble d’outils d’importation qui peuvent recueillir des données sur le réseau de l’e-mail, Twitter, YouTube, Flickr.
Pour Twitter, NodeXL est limité à 18 000 tweets, sur une recherche de 7 jours (maximum théorique, il est rare de dépasser quelques milliers de tweets en pratique). Il faut utiliser la syntaxe de recherche Twitter pour extraire des données via NodeXl, sachant que des variations de requête peuvent donner plus de tweets (par exemple, ajouter lang :fr si la requête est en français) NodeXL permet également d’extraire les données des abonnés / abonnements d’un compte twitter sur plusieurs niveaux (cela prend néanmoins beaucoup de temps).
- Visibrain, outil payant de monitoring sur Twitter, nous permet d’extraire l’ensemble des comptes ayant participé à une conversation sur une thématique choisie et paramétrée. Extraction au format .dot
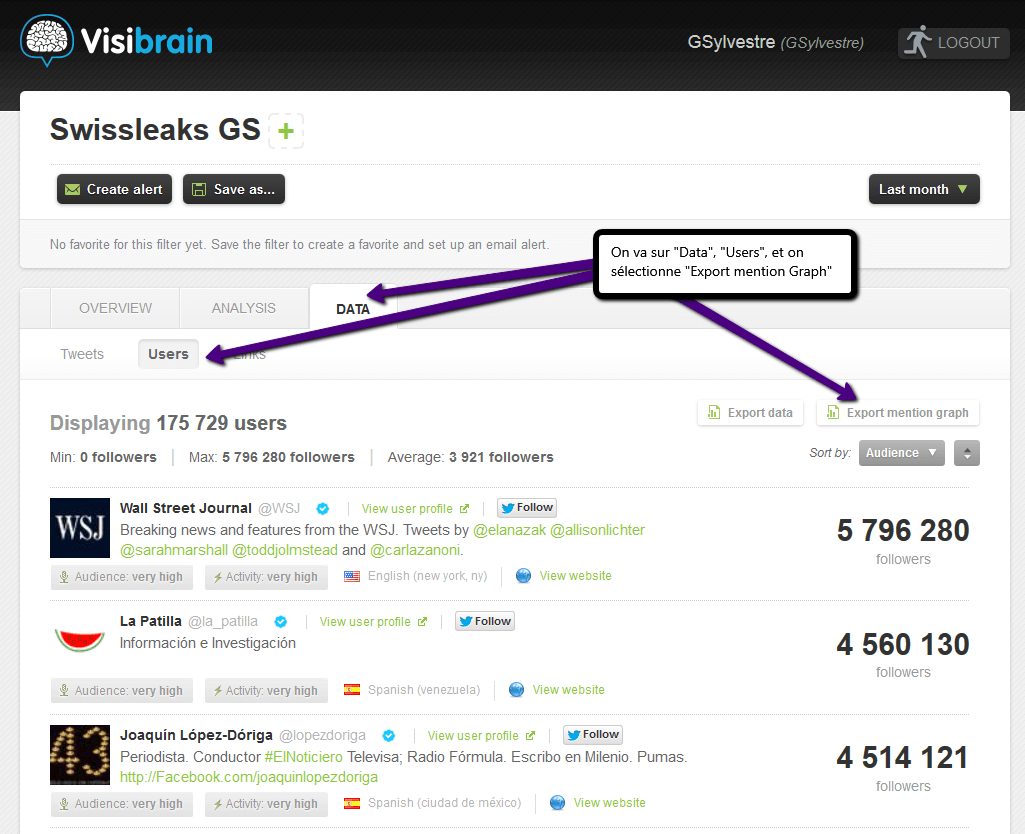
- Netvizz est une application Facebook qui permet d’extraire en GDF pour Gephi :
- Les comptes amis et leurs interactions dans un groupe
- Un réseau de pages connectées entre elles
- L’activité de publication et de commentaire sur une page
Analyse de texte ou d’un corpus : outil de traitement du corpus Automap, gratuit, accessible en ligne.
- Cartographie des corrélations, des relations, des redondances entre les différents termes d’un corpus
1/B Les outils de représentation
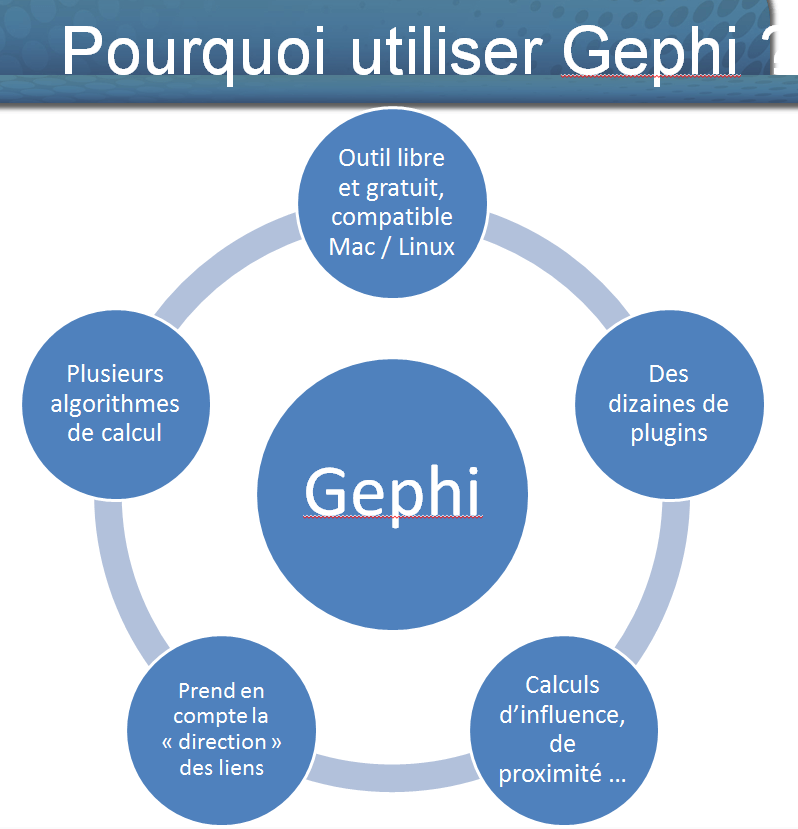
Gephi est un logiciel pour visualiser, analyser et explorer en temps réel les graphes (aussi appelés réseaux ou données relationnelles) de tout type. L’outil permet de représenter, ordonner, agencer les structures, formes et couleurs pour révéler les propriétés cachées d’un réseau via des saillances visuelles.
Les travaux produits sont exportables dans plusieurs formats, notamment le PDF qui permet ainsi d’être visionné par un ensemble large de destinataires. Gephi peut également exporter au format .csv les données importées.
Les formats supportés par Gephi : GEXF14; GDF; DOT (language); GraphML; Graph Modelling Language
Que représenter avec Gephi ?
Sur les réseaux sociaux :
- Les conversations autour d’une thématique (#hashtag ; combinaison de requêtes)
- L’écosystème d’un compte Twitter
- L’activité et l’écosystème d’une page Facebook
Sur le web :
- Dynamique de diffusion et de relations entre des sites web et blogs
Autres possibilités :
- Cartographie textuelle d’un corps de texte (nécessite un travail de filtre avec Automap)
1/C Introduction à la représentation cartographique : notions de base et vocabulaire
Pour produire un réseau, deux informations sont nécessaires: une liste des acteurs composant le réseau et une liste des relations entre ces acteurs. On appellera les acteurs « nœuds » ou « node » et les relations « arêtes » ou « arc ». Le label correspond au nom du nœud donc de l’acteur.
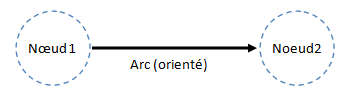
L’arc est orienté, cela veut dire que la relation va du compte 1, au compte 2. Ce type de relation est par exemple utilisé pour montrer que le compte 1 a envoyé un tweet ou suit le compte 2 en fonction des données collectées.
Dans le cas de Twitter, on obtient par exemple deux types de liens si on se centre sur un Node :
- Les liens entrants : Le compte Twitter est suivi / mentionné par une personne identifiée
- Les liens sortants : Le compte Twitter suit / mentionne une personne identifiée
Dans un graphe, un cycle est une chaîne simple dont les extrémités coïncident. On ne rencontre pas deux fois le même sommet, sauf celui choisi comme sommet de départ et d’arrivée.
On parle de « graphe connexe » si chaque node du graph possède au moins un lien de liaison avec tous les autres points. Deux sommets sont adjacents s’ils sont reliés par une arête. Un arbre constitue un graphe connexe ne présentant aucun cycle.
Un graphe est dit complet si toutes les paires de sommets sont adjacentes.
1/D L’interface de Gephi
L’interface se structure autour de 3 onglets pour répondre à ces différents besoins :
- Une vue d’ensemble pour analyser l’information
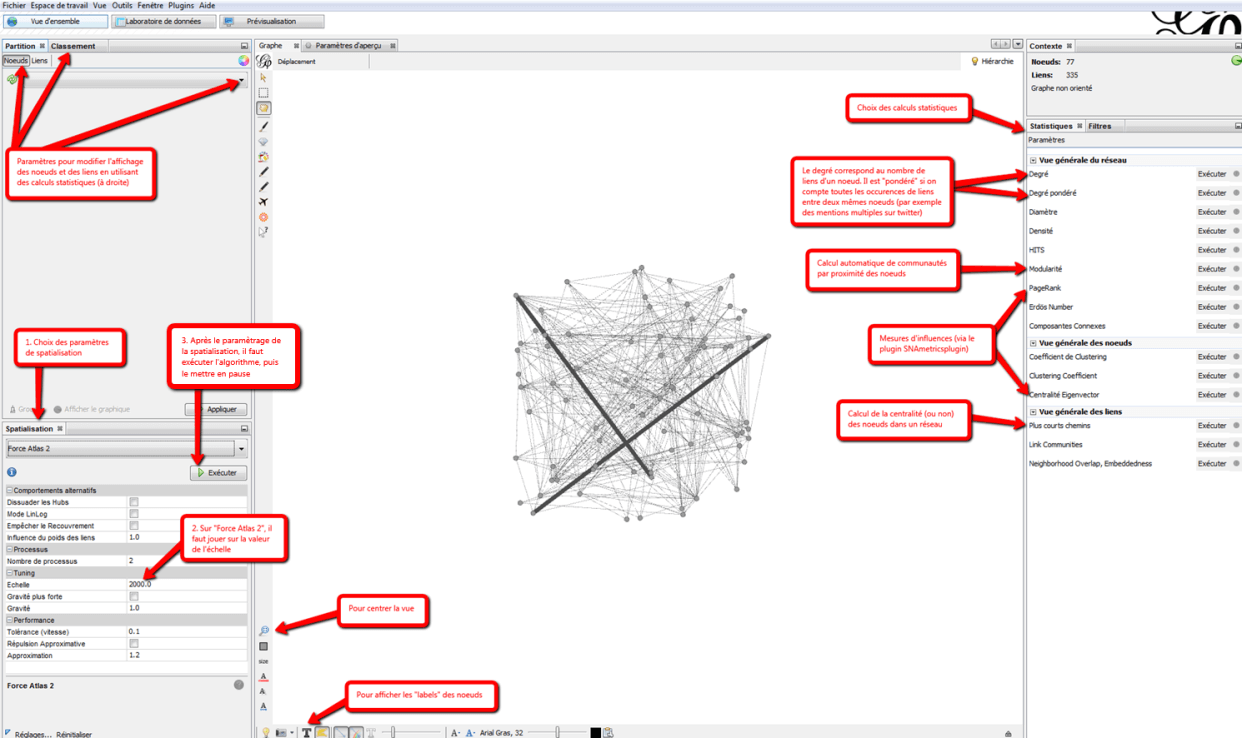
- Un laboratoire des données pour voir vos données : Se présentant sous la forme d’un simple tableau, vous pourrez manipuler vos informations comme vous l’auriez fait sous Excel. Une particularité, le laboratoire de données possède deux onglets en haut à gauche, un onglet Nœuds, et un onglet lien. Vous pourrez donc passer des données concernant les acteurs de votre réseau (les comptes Twitter par exemple), aux données reliant ses acteurs (qui suit /mentionne qui)
- La zone de classement et de partition :dans cette zone, vous allez pouvoir colorier les données en fonction des paramètres obtenus par l’analyse statistique, ou séparer vos données pour leur appliquer des couleurs différentes. Vous pourrez par exemple séparer deux groupes sur le schéma pour les classer en fonction de différentes informations.
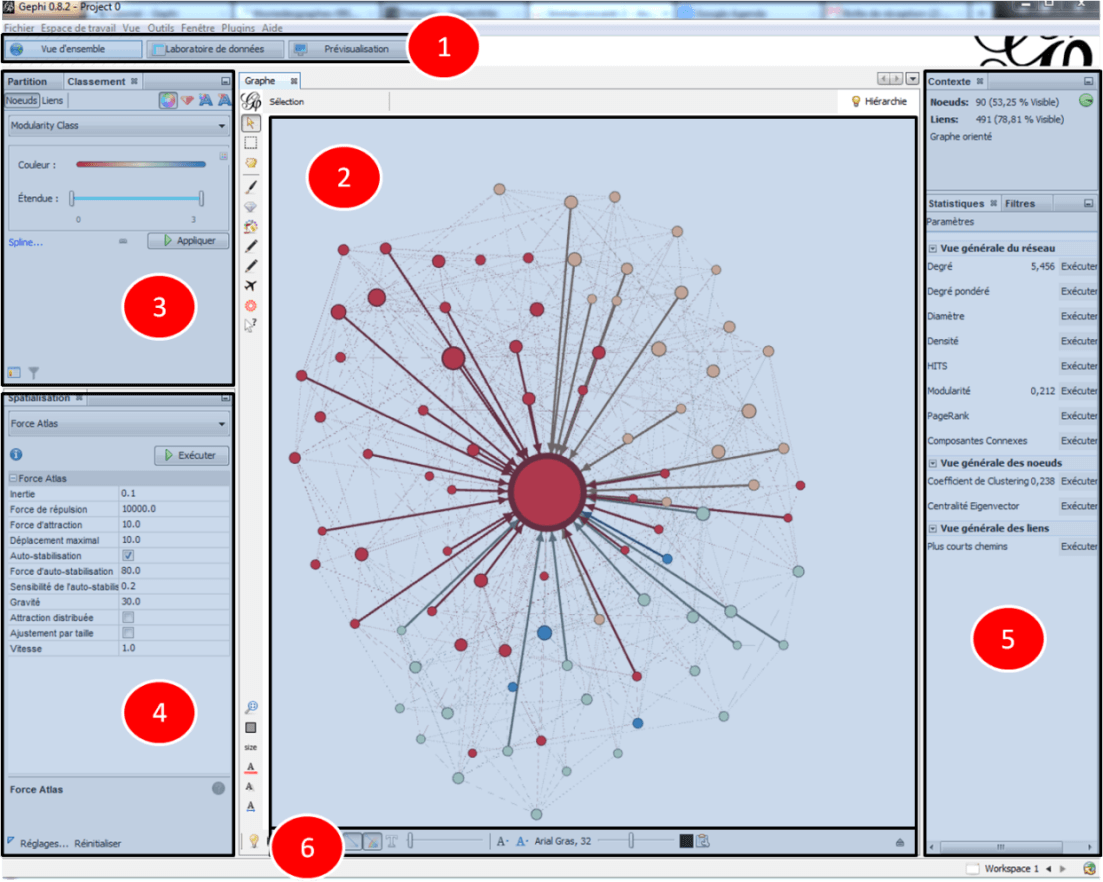
- La zone de spatialisation : cet onglet va vous permettre de choisir un algorithme pour replacer les nœuds (comptes Twitter), au mieux et vous permettre de visualiser leurs interactions.
- Un onglet de filtres et de statistiques: avec cet outil, vous allez pouvoir retirer certains nœuds (comptes Twitter) de votre réseau, filtrer l’information en fonction de certains paramètres, mais aussi effectuer des analyses statistiques.
- L’affichage des données :Cet onglet permet de faire varier la taille des nœuds, des liens entre les nœuds, et d’afficher le nom des nœuds.
2/ Quel(s) algorithme(s) pour quel(s) objectif(s) de représentation ?
La logique des layouts “force based”
Les nœuds se repoussent comme des aimants, tandis que les liens attirent les nœuds qu’ils connectent, tels des ressorts.
Ces forces mettent les nœuds en mouvement, jusqu’à ce qu’un point d’équilibre soit atteint (les nœuds ne bougent plus).
2/A Mettre en avant des divisions entre différents composantes de la cartographie
OpenOrd a pour objectif de mettre en avant des divisions entre les différentes parties de la cartographie.
2/B Mettre en avant des complémentarités entre les différents éléments de la cartographie
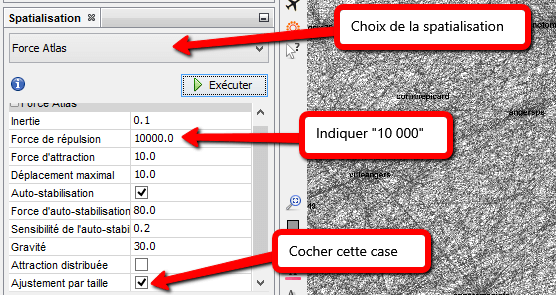
Force Atlas permet de spatialiser des réseaux small-world / sans échelle. Il est axé sur la qualité, pour explorer « des données réelles » et permettre une interprétation rigoureuse du graphique avec le moins de biais possibles, et une bonne lisibilité.
La valeur de la force de répulsion dépend de la densité des nœuds et de leurs relations, l’important étant de bien distinguer les nœuds et de pouvoir lire chaque label (qui s’affiche via le « T » en bas de l’écran). La variable d’ajustement par taille permet d’éviter les chevauchements.
- de 1 à 10 000 noeuds. Opportunité de mettre en exergue le poids des noeuds.
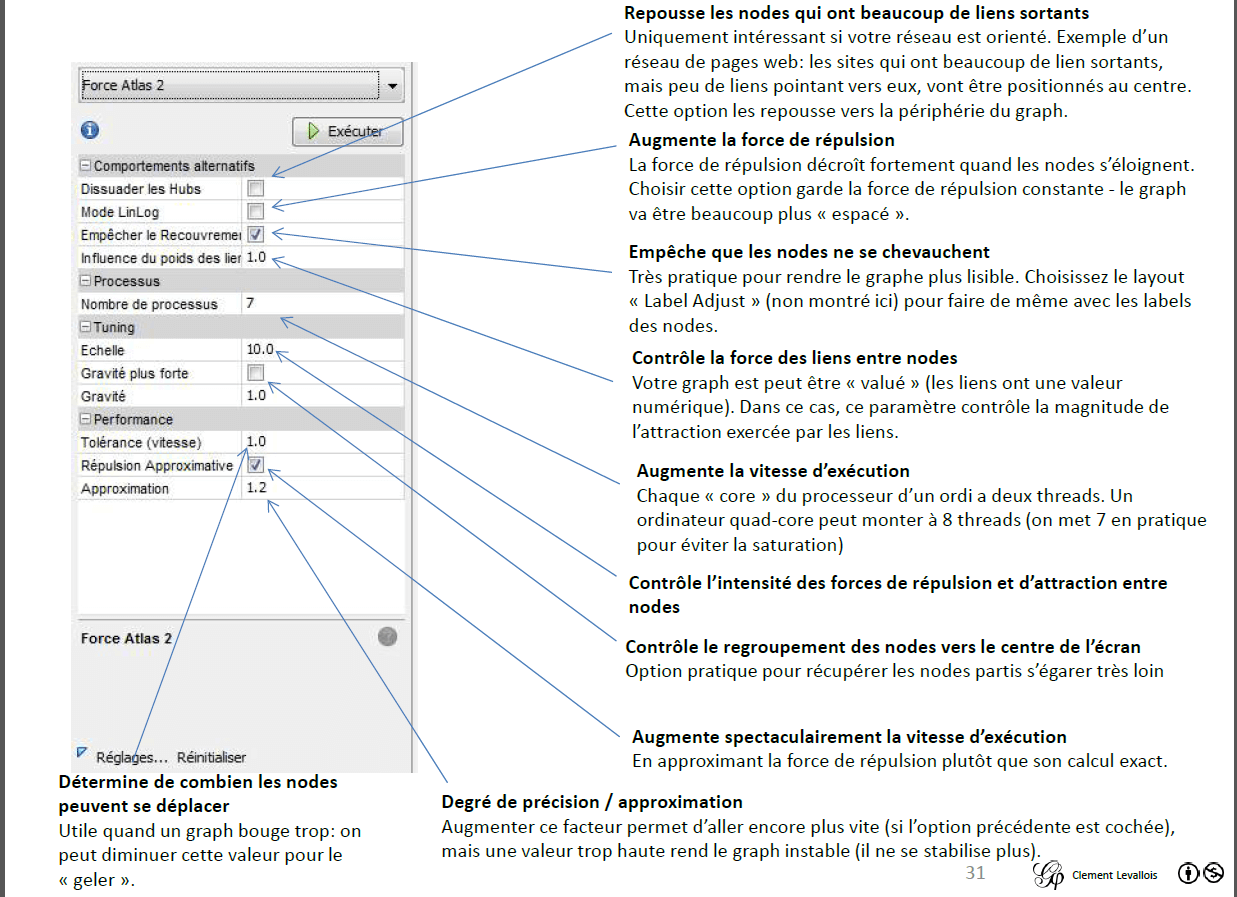
A noter la possibilité d’utiliser « Force Atlas 2 », une version de cet algorithme adaptée pour traiter des réseaux de plusieurs centaines de milliers de noeuds :
Ce qui nous donnera par exemple :
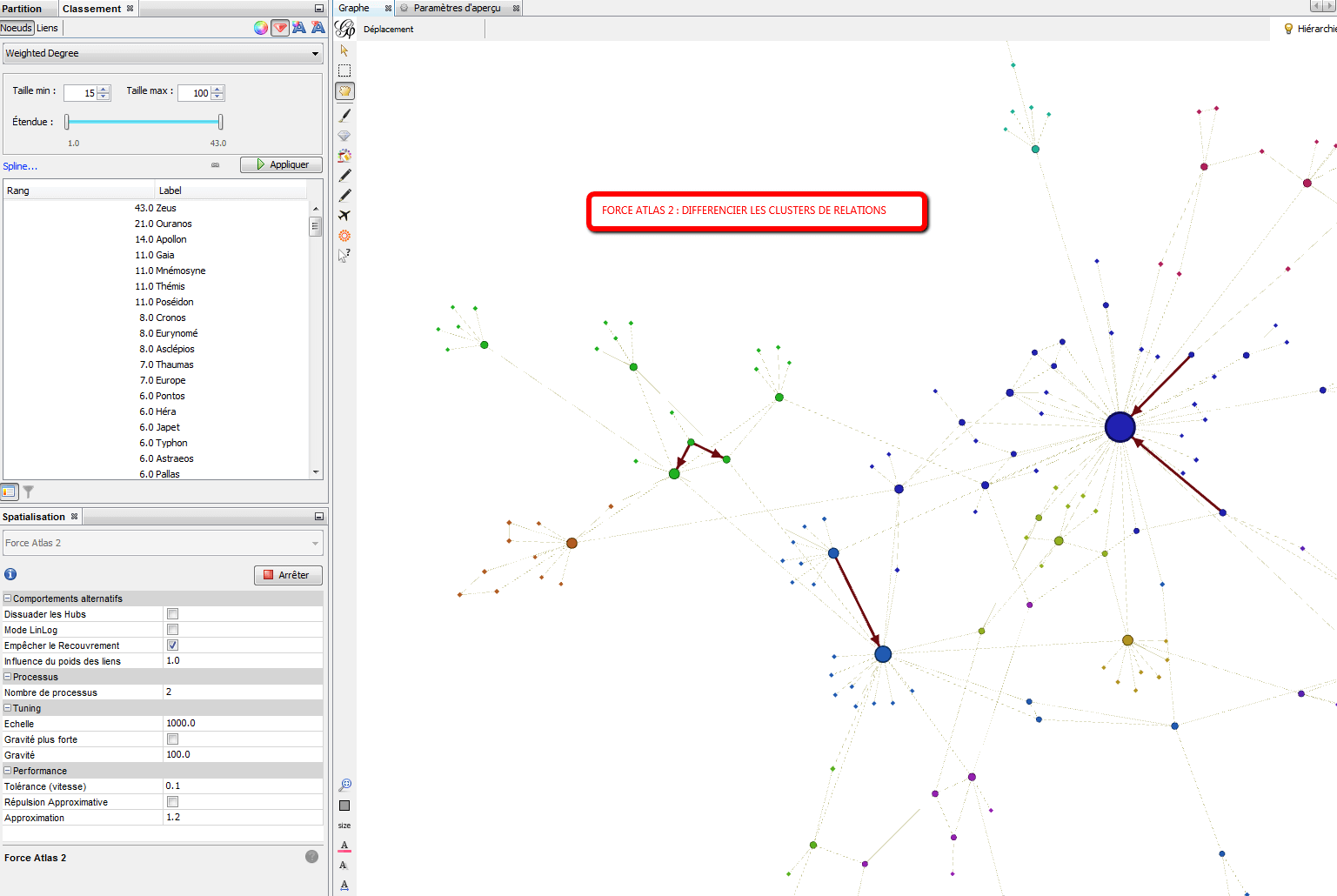
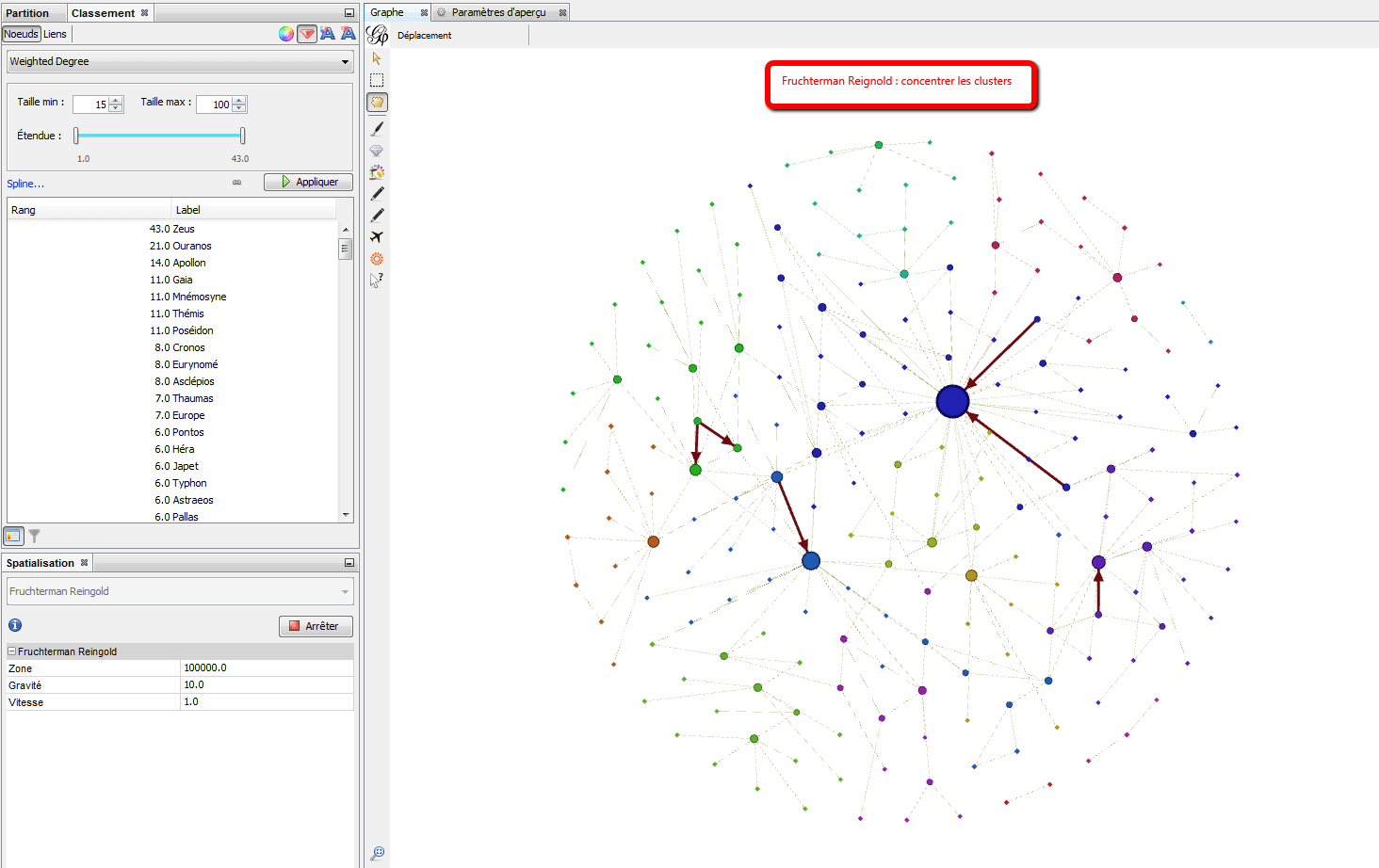
Fruchterman-Rheingold, le layout classique. Les forces s’exercent entre noeuds voisins. Il simule le graphique comme un système de particules de masse. Les noeuds sont les particules de masse et les bords sont des ressorts entre les particules.
- De 1 à 1 000 noeuds. Pas de poids pour les noeuds.
Kamada and Kawai utilise une force d’attraction entre deux noeuds proportionnelle à la taille du chemin le plus court les séparant.
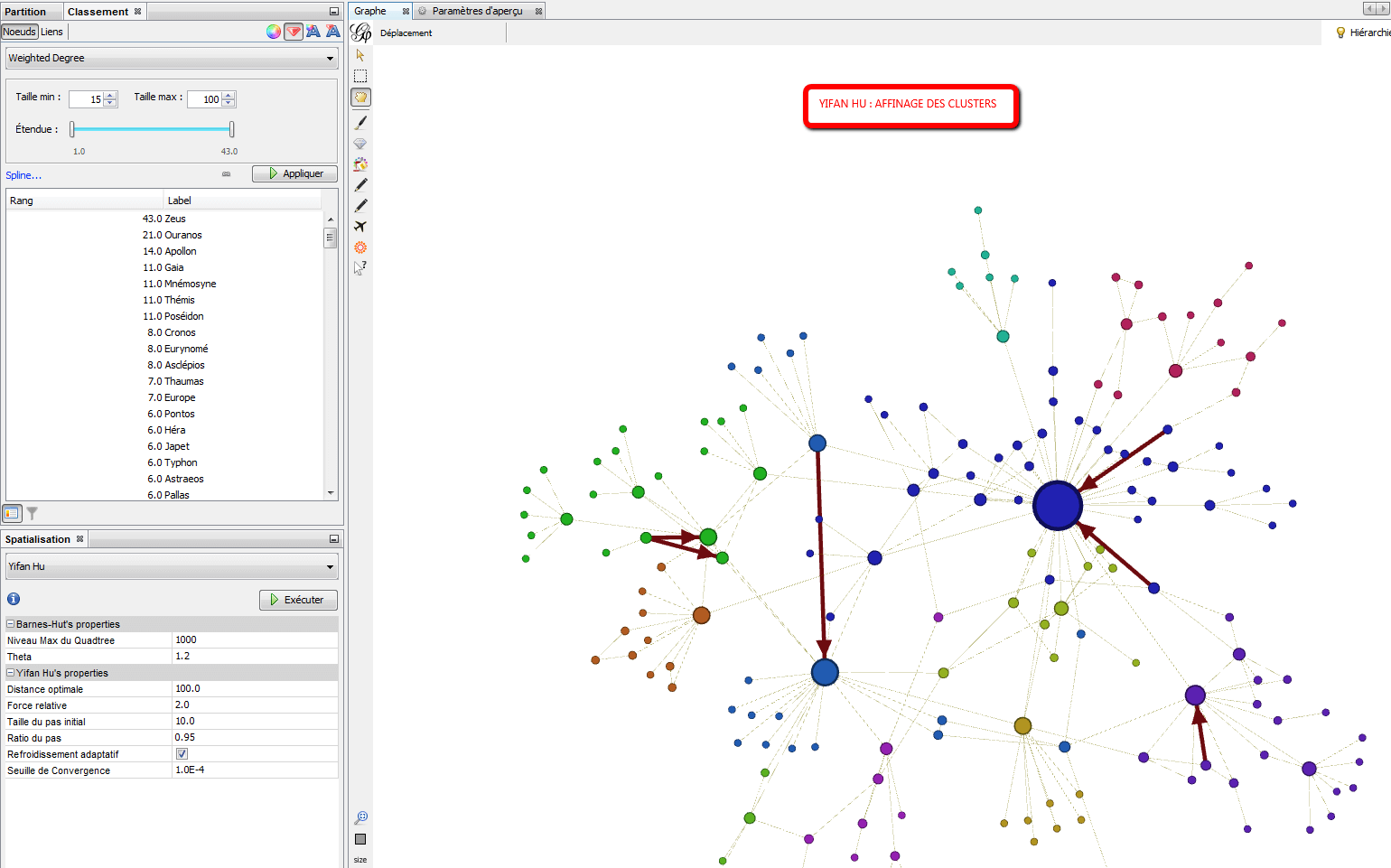
Yifan Hu rassemble les noeuds en groupe, et applique une logique force-based à ces groupes. Il s’agit d’un algorithme très rapide avec une bonne qualité sur les grands graphes. Il combine un modèle de force dirigée par une technique graphique de grossissement (algorithme à plusieurs niveaux) pour réduire la complexité. Les forces de répulsion sur un nœud d’un cluster de nœuds distants sont approchées par un calcul Barnes-Hut, qui les traite comme un super-nœud.
- De 100 à 100 000 noeuds. Pas de poids sur les noeuds.
2/C Mettre en avant une logique de classification des éléments du graphique
Circular Axis Il attire les nœuds dans un cercle ordonné par ID, une métrique (degré, betweenness centralité …) ou par un attribut. A utiliser pour montrer une distribution de nœuds avec leurs liens.
- De 1 à 1 000 000 noeuds
Radial Axis Layout regroupe les nœuds et attire les groupes axes rayonnant vers l’extérieur à partir d’un cercle central. Les groupes sont générés à l’aide d’une métrique (degré, betweenness centralité …) ou un attribut. A utiliser pour étudier les rapprochements en montrant les distributions de nœuds à l’intérieur des groupes avec leurs liens.
- De 1 à 1 000 000 de noeuds.
GeoLayout permet d’obtenir une répartition géographique sur un support de carte. Il utilise des coordonnées latitude / longitude pour définir la position des noeuds sur le réseau. Plusieurs projections sont disponibles, y compris Mercator qui est utilisé par Google Maps et d’autres services en ligne. Les deux colonnes d’attributs de nœud pour les coordonnées doivent être au format numérique.
2/D Autres algorithmes
- Ajustement des labels/noverlap: Éviter que les noms se chevauchent sur votre réseau
- Contraction/expansion: Augmente ou diminue l’espace entre les nœuds
3/ Représenter les nœuds en fonction des différents degrés de centralité
Une caractéristique importante des réseaux est la centralité relative des individus entre eux. La centralité est une caractéristique structurelle des personnes dans le réseau, ce qui signifie que la centralité vous dit quelque chose sur la façon dont cette personne s’inscrit dans l’ensemble du réseau. Les personnes ayant des scores de centralité élevés sont souvent plus susceptibles d’être des leaders, des conduits d’information clés, et d’être les premiers à adopter tout ce qui se répand dans un réseau.
3/A Degree centrality = A combien de personnes un compte peut accéder directement ?
- connectivité locale => les noeuds avec beaucoup de voisins sont centraux / Il s’agit du nombre de liens qui mènent vers ou en dehors du nœud. Il est utile pour évaluer les nœuds qui sont centraux par rapport à la diffusion de l’information et influencer leurs communautés.
Il faut noter que par défaut, le calcul de degré ne prend pas en compte le nombre de liens entre une entité A et une entité B : 15 liens (mentions, RT sur twitter) tout comme 1 seul lien indiqueront un degré de relation. Il faut prendre en compte le poids, ou la pondération, via le calcul du “degré pondéré “sur Gephi (menu statistiques).
Le calcul de la centralité entrante pondérée (weighted in degree) donne un classement des comptes twitter avec le plus de mentions. Le calcul de la centralité sortante pondérée (weighted out degree) classe les comptes twitter en fonction du nombre de tweets où ils ont mentionnés d’autres comptes (typiquement des spammeurs ou des comptes très actifs sur une thématique qui mentionnent des alliés ou des personnes influentes).

3/B Closeness centrality = En combien de temps un compte peut-il toucher l’ensemble du réseau ?
- Cette mesure traduit la distance sociale moyenne de chaque individu à tout autre individu dans le réseau. Elle calcule la longueur moyenne de tous les chemins les plus courts à partir d’un nœud à tous les autres nœuds dans le réseau.
- C’est une mesure de portée, c’est à dire la vitesse à laquelle l’information peut atteindre d’autres nœuds à partir d’un nœud de départ donné.
- En divisant 1 par le chemin du plus court moyen d’un individu à toutes les autres personnes dans le réseau, nous calculons leur centralité de proximité. De cette façon, une personne ayant un lien direct avec tout le monde finit avec un score de proximité de 1. Les personnes qui se connectent à la plupart des autres par de nombreux intermédiaires vont obtenir des scores proximité qui sont de plus en plus proche de zéro.
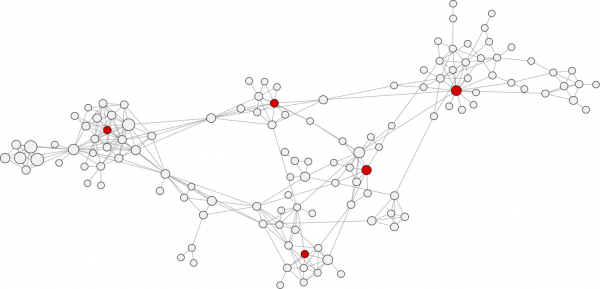
- La proximité de centralité tend à donner des scores élevés aux personnes qui sont près du centre de grappes locales (aka communautés de réseau) dans un réseau global plus important.
Applications : Les comptes à haute proximité de centralité ont tendance à être des influenceurs importants au sein de leur communauté de réseau local. Ils sont souvent des personnalités publiques au sein d’une communauté, d’une profession. Ils sont souvent respectés localement et ils occupent les chemins courts pour diffuser les informations au sein de leur communauté en réseau
Mesure proche : le « Weighted clustering cofficient ». Cette mesure permet de calculer, en modérant en fonction de l’intensité des liens entre les nœuds (donc du nombre de mentions entrantes et sortantes) si les relations des nœuds proches d’un nœud A donné sont toutes connectées entres elles.
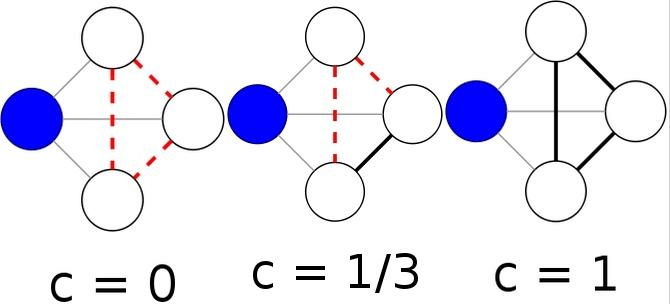
Cette mesure peut donc servir à préciser la closeness centrality en identifiant les nœuds et morceaux des réseaux les mieux connectés par communautés (et donc pour l’analyse twitter savoir si certaines communautés s’appuient sur quelques comptes qui se mentionnent les uns les autres ou alors des ensembles de comptes connectés uniquement via des relations distantes). On parle d’un effet « small world », c’est-à-dire que les membres d’une communauté donnée vont être reliés par un ensemble de petits réseaux locaux interconnectés entre eux.
Exemples :
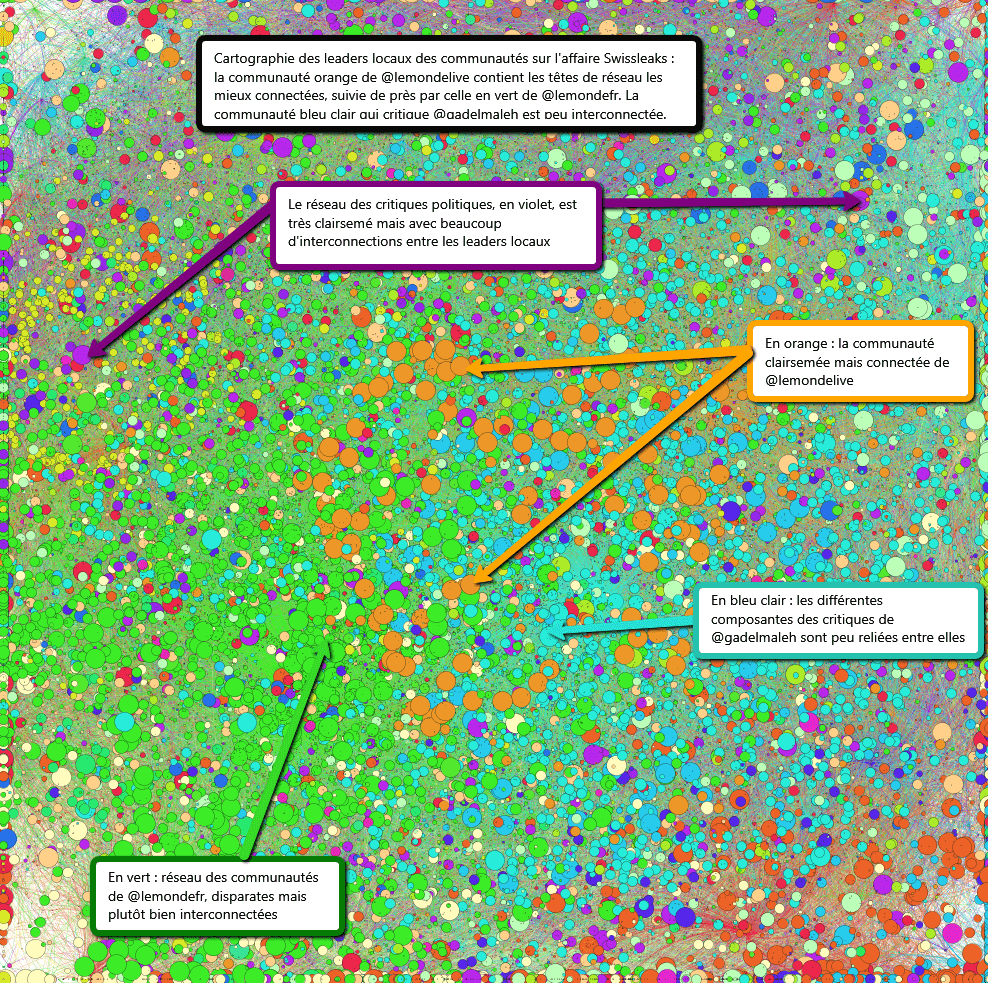
A comparer avec :

La cartographie numéro 2 (closeness centrality) montre une prédominance des leaders locaux de réseaux dans les communautés vertes (@lemondefr), orange (@lemondelive) et bleu clair (@gadelmaleh), et une dispersion des leaders violets (critique politique du swissleaks).
La première cartographie permet de pondérer les résultats et de mieux expliquer la répartition de l’influence des différents groupes (voir calculs suivants). Bien que moins importantes en terme de comptes twitter et de total de mentions, les communautés violettes et oranges obtiennent une certaine influence parce que leurs leaders locaux sont très fortement connectés.
3/C Betweenness centrality (Centralité) = Quelle est la probabilité que cette personne soit l’itinéraire le plus direct entre deux personnes dans le réseau ?
- connectivité => noeuds sur des lieux de passage sont centraux / Et donc de détecter les nœuds les plus susceptibles d’être dans des voies de communication entre les autres nœuds. Également utile pour déterminer les points où le réseau se briserait.
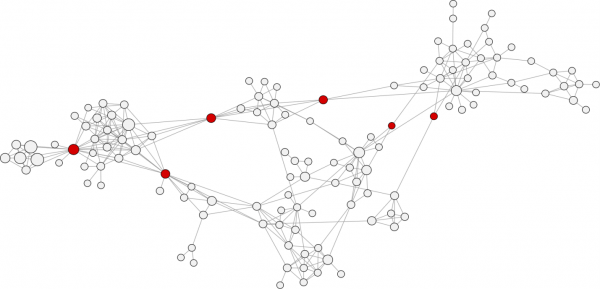
Il s’agit d’une mesure dérivée de la notion de décompte des chemins les plus courts entre les individus dans un réseau. Pour calculer la centralité intermédiaire, on commence par trouver tous les chemins les plus courts entre deux individus dans le réseau. Vous comptez alors le nombre de ces plus courts chemins qui passent par chaque individu. Ce nombre correspond à la centralité intermédiaire.
Ce calcul permet d’identifier les individus qui sont des conduits nécessaires à l’information qui doit traverser des éléments disparates de réseau. Ce sont généralement des personnes très différentes de celles avec une grande proximité. Les individus à forte Betweenness centrality (ou centralité) ne sont souvent pas le chemin le plus court pour joindre tout le monde, mais ils ont le plus grand nombre de chemins les plus courts qui vont nécessairement passer par eux.
Dans un réseau social, les individus avec un score élevé de centralité se trouvent souvent aux intersections des communautés de réseau plus densément connectés.
Applications : En raison de leurs emplacements entre les communautés de réseau, ces comptes à forte Betweenness centrality sont naturellement des courtiers d’information.

La mesure de la Betweeness centrality permet d’identifier plus facilement des réseaux activistes, utiles pour faire passer un message mais pas toujours visibles en termes de mentions.
3/D « Centralité Eigenvector » = A combien de personnes bien connectées ce compte est-il relié ?
Cette analyse statistique permet de déterminer l’importance d’une personne au sein d’un réseau, et donc d’attribuer des valeurs à chaque personne de votre réseau. Une fois cette statistique calculée, vous pouvez aller sur le panneau de classement en haut à droite, et affecter une taille en fonction du paramètre « eigencentrality ». Vos données doivent être entre une taille minimum de 10 et maximum de 50. Utile pour déterminer qui est connecté aux nœuds les plus connectés.
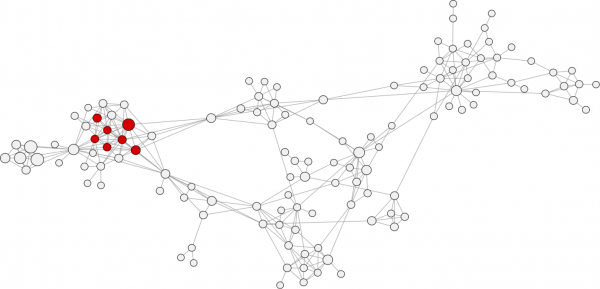
Cette mesure désigne essentiellement le fait qu’un individu est un compte autoritaire connecté à d’autres comptes autoritaires au sein d’un vaste réseau. Eigenvector centralité est calculée en évaluant la façon dont un individu est relié aux parties du réseau avec la plus grande connectivité. Les personnes ayant des scores élevés de vecteurs propres ont de nombreuses connexions, et leurs connexions ont de nombreuses connexions, et leurs connexions ont de nombreuses connexions … jusqu’au bout du réseau.
Applications: Les individus possédant un vecteur propre de centralité élevé sont considérés comme les leaders du réseau. Ce sont souvent des personnalités publiques avec de nombreux liens avec d’autres personnes à haut profil. Ainsi, ils jouent souvent des rôles de leaders d’opinion clés et façonnent la perception du public. Un exemple de cela est l’algorithme page rank de Google, qui est étroitement liée au vecteur propre de centralité calculé sur des sites Internet basés sur les liens pointant vers eux.
Ces comptes ne peuvent cependant pas effectuer nécessairement les rôles de haute proximité et intermédiarité. Ils n’ont pas toujours la plus grande influence locale et peuvent avoir un potentiel de courtage limitée. Comme un roi à l’écart dans sa cour ou le directeur général dans sa salle de réunion , ils peuvent parfois être isolés des individus et des communautés périphériques de réseau de petite taille qui ont une connectivité limitée avec les parties les plus densément connectés du réseau .
Les Hubs concentrent les liens sortants. Ils correspondent à des comptes chargés de redistribuer l’information à une communauté. Les Autorités centralisent les liens entrants. Ces liens se traduisent par des mentions, des sollicitations ou des références à un compte source.
3/E Modularity class = Identifier les relations entre les nœuds et mettre en avant des communautés
Le filtre statistique Modularity Class est disponible dans l’onglet statistique à droite, qui s’appelle plus communément modularité. Il va détecter automatiquement si des personnes de votre réseau semblent liées entre elles. Ce calcul est pertinent à partir de plusieurs milliers de relations. Ce filtre va déterminer les communautés à l’intérieur du graphe, c’est à dire des ensembles de sommets fortement reliés entre eux, ce qui revient, dans la majeure partie des cas, à déterminer des groupes d’individus qui ont tendance à se retweeter, à s’interpeller ou à se mentionner.
| Modularité (Newman 2004) :Nombre de liens dans chaque groupe moins le nombre de liens dans les mêmes groupes, dans un graph ou les liens auraient été redistribués de façon aléatoire.Trouver les communautés dans un graph = définir des groupes de façon à ce que le score de modularité soit le plus élevé. |
Pour afficher cette information sur la carte, vous devez vous rendre par la suite dans l’onglet partition en haut à gauche, et sélectionner la statistique que vous avez créée, « modularity class ». En appliquant cette partition, les couleurs de votre réseau vont se modifier, et mettre en avant les relations entre les personnes. question game Il peut être utile de modifier les couleurs par défaut, Gephi ayant tendance à choisir des couleurs sombres assez semblables pour les principales communautés, ce qui peut engendrer des confusions.
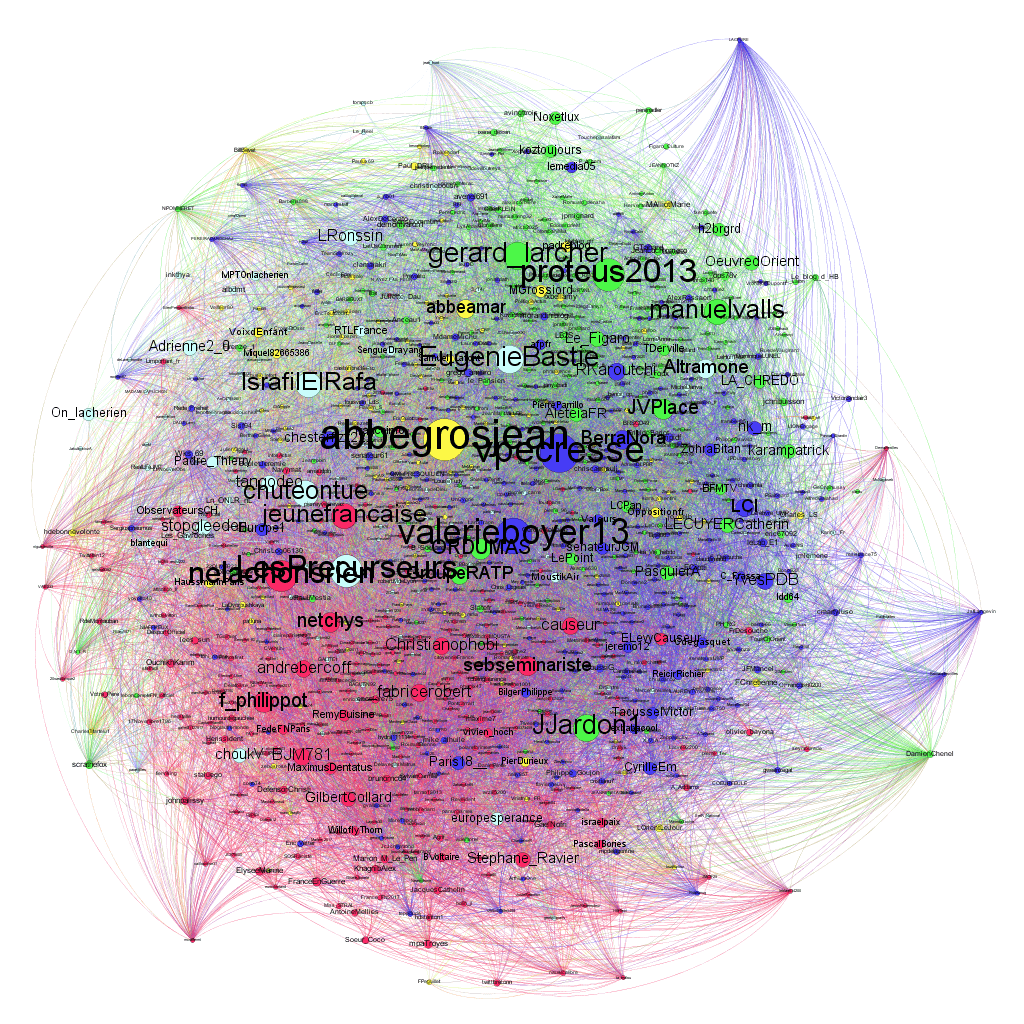
Comme le présente la cartographie ci-dessous correspondant au buzz contre la RATP après le retrait d’affiches de publicité soutenant les chrétiens d’orient, après calcul et utilisation du filtre, la modularité met en évidence 4 espaces de conversation distincts :
– vert : sphère “institutionnelle” : responsables politiques et religieux et leurs correspondants ;
– bleu : leaders d’opinion ancrés à droite et leurs correspondants ;
– bleu clair : militants catholiques radicaux et leurs correspondants ;
– jaune : abbés Grosjean et Amar et leurs correspondants ;
– rose : leaders d’opinion d’extrême-droite et leurs correspondants.
3/F Aller plus loin dans l’analyse en combinant des filtres
| Faible nombre de mentions | Faible score de proximité | Faible centralité dans le réseau | |
| Fort nombre de mentions | Compte twitter membre d’un cluster éloigné du réseau | Connections du compte twitter redondantes et ne passant pas par lui | |
| Fort score de proximité | Compte twitter relié à des comptes très actifs ou influents | Compte twitter relié à plusieurs autres comptes mais pas central | |
| Forte centralité dans le réseau | Compte twitter essentiel pour la diffusion à certaines communautés | Compte twitter sert de lien exclusif entre le reste du réseau et un cluster |
Il est également possible via les filtres de Gephi de combiner des calculs statistiques, pour raffiner les résultats obtenus et identifier des comptes twitter aux propriétés spécifiques :
Exemple : Croisement entre le filtrage des comptes twitter les plus mentionnés et la variation de leur taille par valeur de betweeness centrality sur les tweets français de SwissLeaks

On voit sur la cartographie des comptes les plus mentionnés que le compte @gadelmaleh est très mentionné, tout comme celui du @mondefr. Mais est-il central dans les discussions, et surtout est-il à l’origine lui-même de ces mentions ?

La cartographie du croisement des informations « mentions / degré » et « centralité / betweeness » nous indique que si @gadelmaleh a beaucoup de mentions, il a une faible centralité dans le réseau : les connections ne passent pas par lui, et c’est bien normal, puisque l’acteur est mentionné à l’insu de son plein gré !
A l’inverse, on constate que le compte @gracchusX, qui est très visible sur la deuxième cartographie, a donc un fort score de betweeness centrality, sans être énormément mentionné : il sert de passerelle avec une communauté spécifique.
On peut également, sous réserve de disposer d’un fichier enrichi, ajouter autant de filtres qu’il y a de données à comparer. Par exemple, NodeXL propose, en récupérant les mentions entre comptes twitter sur une recherche donnée, d’ajouter les données suivantes au fichier excel exportable – Visibrain proposera prochainement des exports enrichis également :
- Pour les liens : type de tweet (mention, réponse, RT) ; date du tweet ; nom de domaine d’une éventuelle URL présente ; hashtags utilisés : coordonnées du tweet (si géolocalisés – latitude et longitude)
- Pour les noeuds (comptes twitter ici) : nombre d’abonnés, nombre d’abonnements, total de tweets, total de favoris, location, zone horaire, date de création du compte …
A noter que pour tirer profit de ces informations supplémentaires, il faut préciser en les important leur type : texte, nombre, données temporelles … et les filtres de Gephi s’adapteront en conséquence.
Cela permet d’effectuer des analyses très précises en intégrant à la fois les calculs de statistiques propres à Gephi et des filtrages liés à la nature des données importées dans Gephi.
BONNE NOUVELLE, VISIBRAIN INTÈGRE MAINTENANT CES DONNÉES AUX EXPORTS (format GEXF). Le gros avantage par rapport à NodeXL est qu’il n’y a pas de manipulation à effectuer pour utiliser ces filtres additionnels, notamment le filtre temporel.
Un exemple concret avec la cartographie des tweets concernant le scandale des frais de taxis de l’ex directrice de l’INA :
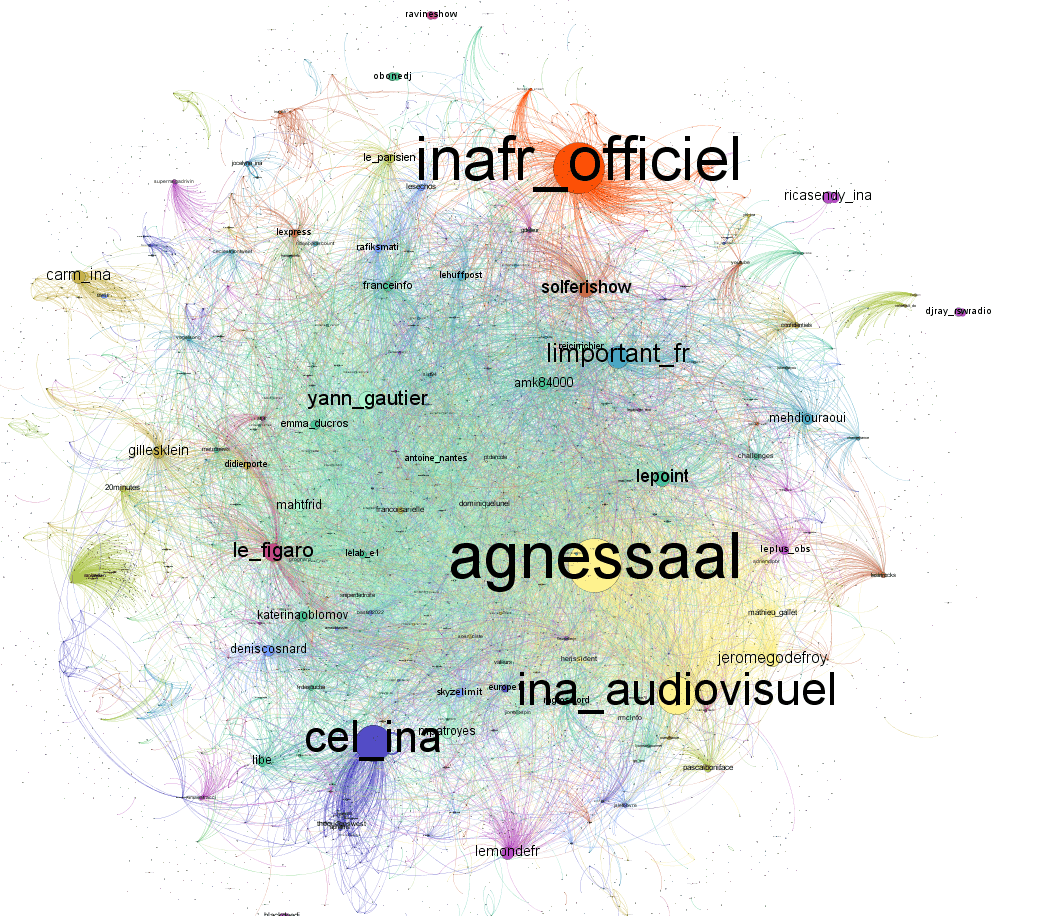
On a ci-dessus la carte des comptes les plus mentionnés. On peut maintenant l’affiner en affichant uniquement les comptes parmi cette cartographie qui ont un nombre important d’abonnés, pour voir si ce sont bien ces comptes qui sont à l’origine du buzz :

On voit bien que les comptes avec le plus d’abonnés ont très peu contribué à la propagation du buzz. Ce sont principalement des médias qui ont repris l’information sans en être à l’origine.
Il est également possible de filtrer les labels des noeufs affichés dans l’export d’une cartographie, afin de la rendre plus lisible :
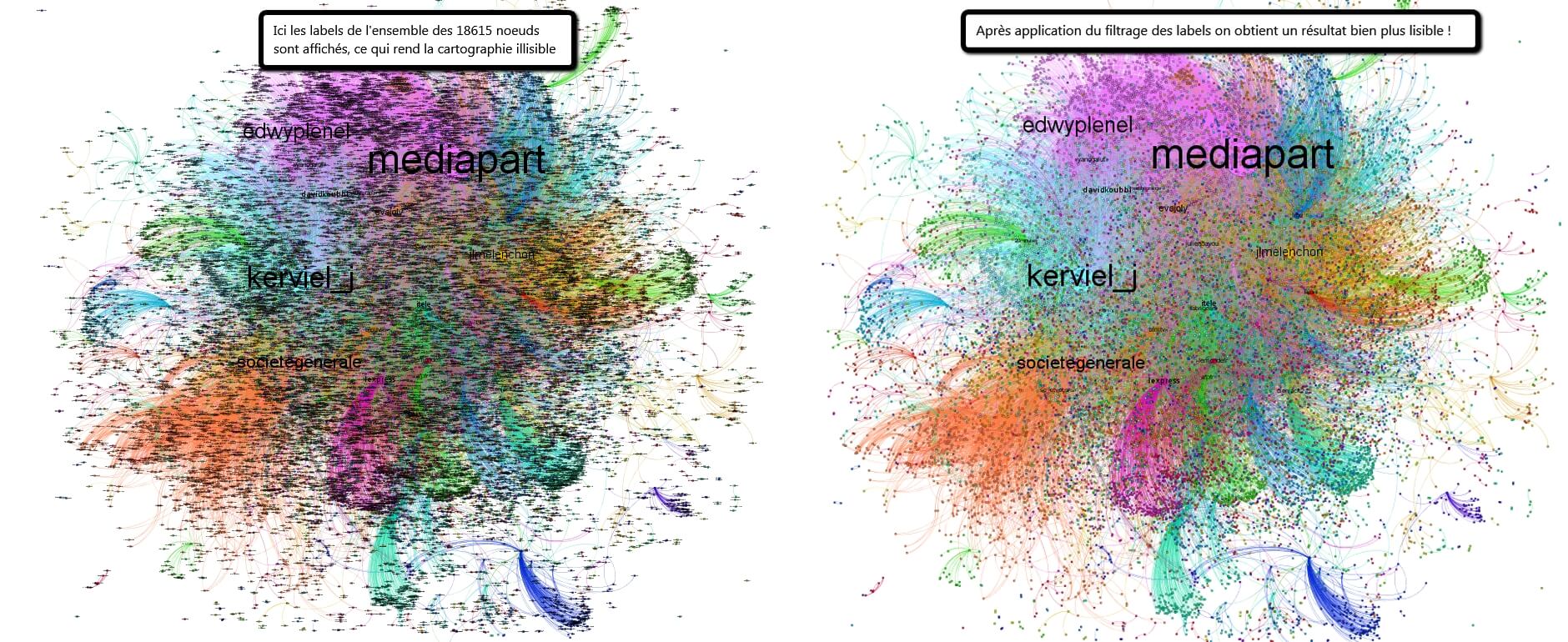
La procédure est assez simple à mettre en place. Après avoir choisi un filtre sur Gephi et validé l’affichage des labels sur l’espace de travail, il suffit de sélectionner une plage de valeurs (et non de la “filtrer”) puis de cliquer sur le masquage des labels hors de la sélection :

4/ SIGMA : L’export analytique et esthétique
Sigma (http://sigmajs.org/) est une fonction d’export très aisée à installer puis à utiliser pour faciliter l’analyse de la cartographie ainsi qu’améliorer son esthétique et sa compréhension.
Installation :
Rendez-vous sur https://marketplace.gephi.org/plugin/sigmajs-exporter/ pour télécharger le template puis l’installer dans Gephi. Seconde solution, plus simple, vous pouvez également vous rendre directement dans Gephi puis dans Outils ➔ Modules d’extension puis rechercher Sigma.js dans les modules d’extension disponibles.
Export :
Une fois votre travail de représentation des données sur Gephi, rendez-vous dans Fichier puis Exporter, choisissez enfin le format sigma.js

A savoir, l’export Sigma.js créé un dossier de fichier appelé par défaut « network », qu’il est obligatoire de garder ou de déplacer dans sa totalité. Afin de lire votre cartographie, il vous faudra ouvrir le fichier « index.html» avec Mozilla Firefox et uniquement Mozilla.
Esthétique et analyse de la représentation

L’esthétique est bien plus harmonieuse qu’avec Gephi, en mode Flat Design. Sigma.js vous permet :
- cliquer sur un nœud et isoler son réseau de relations au sein du réseau gobal
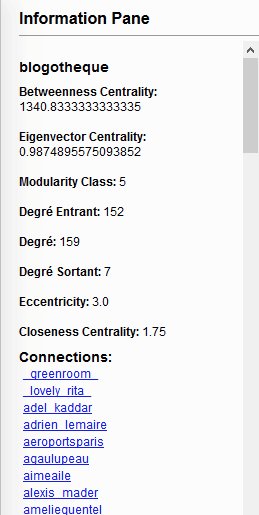
- rechercher un nœud grâce à son username
- obtenir un large éventail d’informations sur chacun des nœuds (Betweenness centrality, Eigenvector centrality, degré entrant et sortant, la modularité, l’ensemble des comptes en relations) ➔ Ces informations émanent de la qualité des méta-données avant le travail dans Gephi mais aussi en fonction des statistiques et filtres utilisés pour réaliser la cartographie.
Chargé de veille et d’études à La Netscouade
Consultant en veille et e-réputation à l’ADIT