Le domaine de la santé gère quotidiennement des quantités remarquables de données issues de systèmes d’information cliniques et opérationnels comme le dossier électronique du patient. Les professionnels de santé développent de nouvelles applications pour élargir considérablement les opportunités pour les intervenants afin d’obtenir une plus grande valeur.
L’analyse Big data dans le domaine de la santé intègre des méthodes d’analyse de quantités considérables de données électroniques liées aux soins de santé des patients. Ces données sont extrêmement variables et difficiles à mesurer avec les logiciels et le matériel traditionnels. Il existe divers types de données de santé.
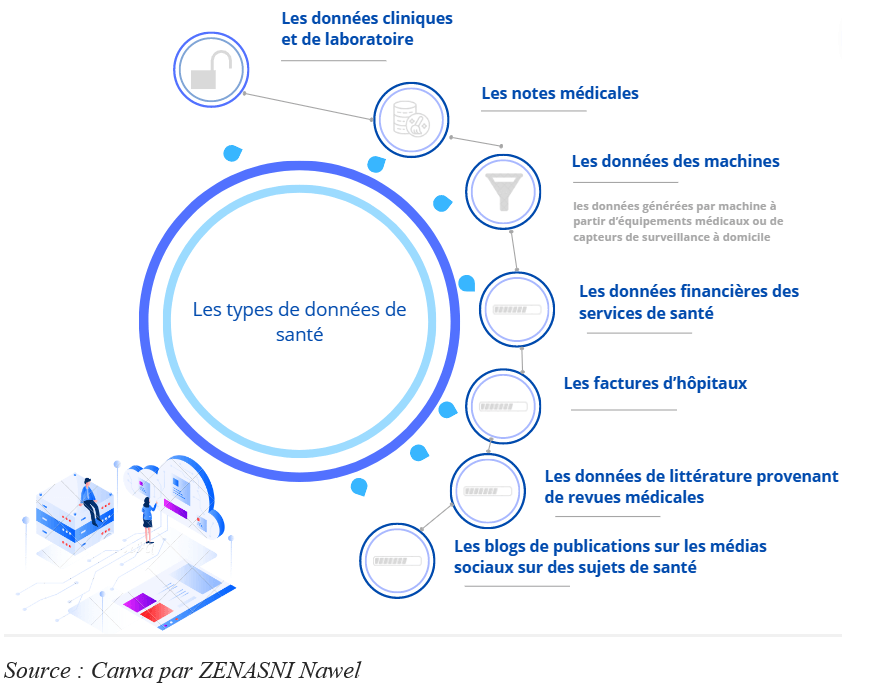
Ces données sont disponibles au sein de différents services de santé ou de sources externes (par exemple les compagnies d’assurance ou les pharmacies). Elles sont structurées (tableaux contenant les résultats des tests) ou non structurées (par exemple, le texte d’une lettre d’un médecin).
Le Big Data est reconnu par quatre caractéristiques, appelées 4V.

Les méthodes utilisées pour les mégadonnées font référence à de nombreuses outils.

Les informaticiens créent régulièrement de nouvelles applications pour aider les professionnels de la santé à développer des opportunités à plus forte valeur. Les organisations bâtissent également des infrastructures avec de grandes capacités en big data pour améliorer la prise de décision.
Le machine learning dans le domaine de la santé
Le machine learning est la technique d’analyse la plus appropriée pour de nombreux types de données et bénéficie d’un grand potentiel pour améliorer les résultats de nombreux domaines de recherche dans le domaine de l’analyse prédictive de la santé. Il facilite considérablement le développement de modèles centrés sur le patient pour améliorer le diagnostic et l’intervention. Le machine learning est une technique d’analyse de données qui automatise fortement la création de modèles analytiques. Les techniques de machine learning peuvent être utilisées pour intégrer parfaitement et interpréter notamment des données de santé complexes dans des scénarios où les méthodes statistiques traditionnelles échouent. Divers modèles de machine learning axés principalement sur la prédiction des risques sont généralement évalués afin que le modèle le plus précis soit sélectionné.
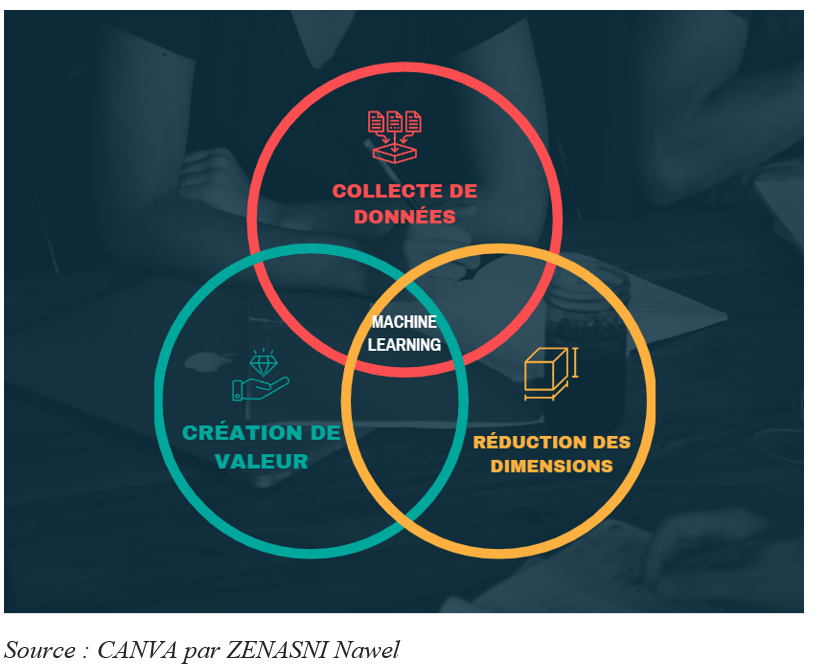
Le machine learning est important dans chaque phase du big data.
Les algorithmes du machine learning se sont révélés utiles dans le diagnostic médical, comme la détection du diabète, où des modèles prédictifs plus précis sont nécessaires. Et dans des domaines médicaux comme l’oncologie, où la reconnaissance des formes est importante, comme la radiologie.
Analyse des mégadonnées
Le Big data sont des données si volumineuses qu’elles ne peuvent pas être traitées par l’informatique de santé traditionnelle en tant que « système autonome » à l’aide d’un simple logiciel d’analyse. Dans ce contexte ce qui est nécessaire, c’est un modèle plus complexe, à programmation intensive, avec une immense variété de fonctionnalités. La plate-forme open source Hadoop est une référence en la matière.
Le cas d’Hadoop
Un cas d’utilisation de l’écosystème Hadoop est présenté dans une brillante étude de Batarseh et Latif (2016) qui a créé un outil appelé CHESS. CHESS déplace les ensembles de données téléchargés vers Hadoop et place les données agrégées avec beaucoup moins de lignes dans les serveurs SQL pour l’analyse. Par la suite, les utilisateurs y accèdent via le logiciel statistique de leur choix (Excel, Tableau, R, etc.), transforment les données dans le format souhaité. Puis exécutent des tests statistiques pour déterminer l’importance de certains facteurs (par exemple, la démographie) en lien avec certaines données de santé.
L’application s’appuie sur Hadoop pour gérer notamment les problèmes de mégadonnées, permettant aux utilisateurs d’interroger uniquement de petites quantités de données avec un logiciel statistique.
Une nouvelle approche a été trouver en 2016, pour favoriser le contenu des données de santé non structurées. Ainsi engendrer la récupération et le traitement de données de santé structurées et non structurées pour des examens de santé personnalisés. Il s’agit d’une amélioration, car la plupart des applications se limitent à interroger uniquement des données médicales structurées.
En effet, lorsqu’il s’agit de traiter des images médicales et des dossiers médicaux, il importe des logiciels et des plateformes basés sur le cloud tels que LifeImage, qui peuvent partager et acquérir des images médicales volumineuses et d’autres dossiers médicaux. Cependant, il se limite à utiliser des données structurées (par exemple, interroger le poids du patient), à acquérir toutes les images et tous les enregistrements pertinents et à traiter des données non structurées. Certaines des limitations techniques qui ressortent des ensembles de données sur l’environnement Hadoop est que le contenu non structuré des données de santé et des images médicales ne peut pas continuellement être traité de la manière souhaitée.
Une telle approche favorise davantage les professionnels de la santé à bénéficier d’une aide à la prise de décision à partir d’algorithmes automatisés.
Conclusion
Les sources de données volumineuses et des techniques analytiques permettent notamment aux capacités de données volumineuses d’engendrer davantage de valeur. Cela sera davantage facilité par de nouvelles recherches dans ce domaine.
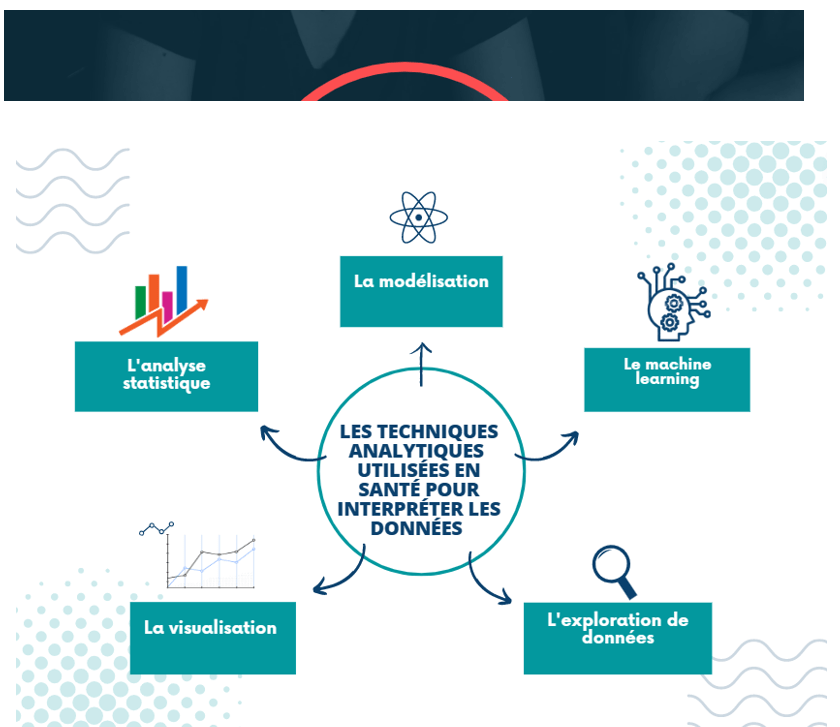
En particulier, le machine learning est la technique la plus couramment appliquée à tous les types de données créées, bénéficiant d’un grand potentiel d’amélioration des résultats. Et ceci, dans de nombreux domaines de recherche dans le domaine de l’analyse prédictive de la santé. Le machine learning est décrit comme un domaine complexe proposant de nombreux types d’outils, de techniques qui peuvent être utilisés pour relever les défis posés par la fusion de données. Par ailleurs, il est également apparent que toutes les technologies appliquées sont utilisées de façon différente dans le big data. Élaborant ainsi des capacités différentes dans le secteur de la santé. Les données cliniques étaient la source la plus couramment utilisée pour l’analyse des données (70 %).
En se basant sur la présentation du logiciel basé sur Hadoop. Cette analyse confirme que les professionnels de santé utilisent principalement des données cliniques ou médicales structurées ou non structurées dans leurs recherches pour développer de nouvelles approches de bilans de santé personnalisés. Par ailleurs, Hadoop permet de concevoir également des modèles commerciaux pour réduire le temps et les coûts de recherche et de traitement tout en maintenant la qualité des données.
Il existe un besoin évident dans le domaine de la santé pour soutenir activement ou améliorer considérablement les capacités de prise de décision des professionnels cliniques. Notamment pour diagnostiquer des maladies et des conditions complexes. Un problème majeur avec les mégadonnées dans le domaine de la santé est que la plupart des données sont souvent non structurées. Cela signifie clairement qu’il existe des obstacles au traitement informatique de la plupart des données. Les experts cliniques s’efforcent donc constamment de développer davantage l’infrastructure pour une analyse la plus efficace possible.
Par Nawel Zenasni, promotion 2022-2023 du M2 IESCI
Références bibliographiques
- Bendahou, M. (2018). Objets Connectés et Big Data au service de l’E-santé. UNIV EUROPEENNE.
- Bertucci, F., Le Corroller-Soriano, A. G., Monneur, A., Fluzin, S., Viens, P., Maraninchi, D., & Goncalves, A. (2020). Santé numérique et « cancer hors les murs » , Big Data et intelligence artificielle. Bulletin du Cancer, 107(1), 102‑112. https://doi.org/10.1016/j.bulcan.2019.07.006
- Wyber, R., Vaillancourt, S., Perry, W., Mannava, P., Folaranmi, T., & Celi, L. A. (2015). Big data in global health : improving health in low- and middle-income countries. Bulletin of the World Health Organization, 93(3), 203‑208. https://doi.org/10.2471/blt.14.139022
- Béranger, J. (2016). La valeur éthique des Big data en santé. Les cahiers du numérique, 12(1‑2), 109‑132. https://doi.org/10.3166/lcn.12.1-2.109-132
- Reza Soroushmehr, S. M., & Najarian, K. (2016). Transforming big data into computational models for personalized medicine and health care. Dialogues in Clinical Neuroscience, 18(3), 339‑343. https://doi.org/10.31887/dcns.2016.18.3/ssoroushmehr
- Rial-Sebbag, E. (2017). Chapitre 4. La gouvernance des Big data utilisées en santé, un enjeu national et international. Journal international de bioéthique et d’éthique des sciences, 28(3), 39. https://doi.org/10.3917/jib.283.0039
Vidéos :
- Cité des sciences et de l’industrie. (2020, août 5). Big data et santé[Vidéo]. YouTube. https://www.youtube.com/watch?v=s8MMg2ps1i0
- France Culture. (2021, 17 septembre). Santé : promesses et dangers du big data[Vidéo]. YouTube. https://www.youtube.com/watch?v=Ykyy_yNufkA