Aujourd’hui de plus en plus d’innovations et technologies révolutionnaires voient le jour. Ces technologies ont le potentiel de considérablement changer notre façon de vivre dans les années qui viennent. L’une d’entre elles est le Big Data, et toutes les technologies et logiciels qui reposent sur celle-ci. Un des secteurs qui pourrait potentiellement être l’un des plus affectés par les technologies du Big Data, est le secteur de la santé. Les enjeux ici sont extrêmement importants, il s’agit de la vie et de la santé de tous.
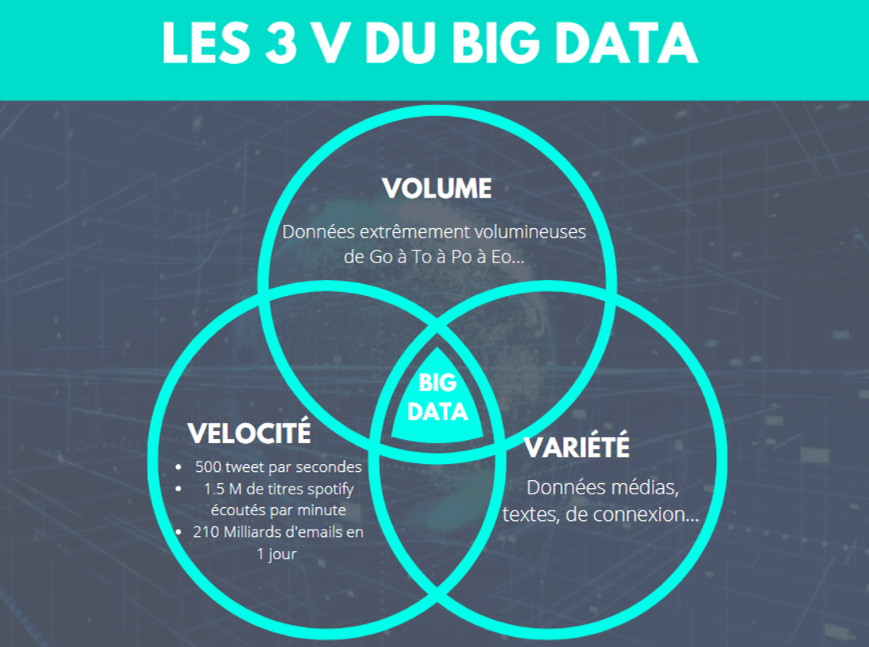
Mais qu’est-ce que le Big Data exactement ? Ce terme étant si souvent employé, sa compréhension de celui-ci peut être floue et nous échapper. La CNIL définit le Big Data, un ensemble de données massives. Plus précisément, ces données doivent répondre à plusieurs critères, appelés couramment les 3V, qui sont le volume, la variété et la vélocité.
Certaines définitions ajoutent d’autres critères, mais ceux-ci varient en fonction des définitions. Seuls les 3V restent constants.
Cette technologie révolutionnaire commence déjà petit à petit à faire sa place dans le secteur de la santé, et les prospects futurs de son utilisation sont déjà pensé et recherché. Son utilisation n’est pas encore massive, mais c’est une part grandissante dans ce secteur. On parle par exemple en France, de l’instauration d’un Health data Hub. Il s’agit d’une base de données médicale de santé commune à tous les Français, qui reposerait sur les technologies du Big Data. Elle regrouperait toutes les données de santé des français, de manière anonyme, et permettrait de faciliter la recherche médicale
Cependant, malgré des avantages clairs de son utilisation, les règles qui entourent le Big Data dans le secteur de la santé ne sont pas strictement définies, et cela comporte des risques, physique, morale et éthique. Nous posons donc la question, quels sont les moyens d’intégrer l’éthique dans l’e-santé ? Pour ce faire, nous définirons d’abord l’environnement qui l’entoure, puis nous montrerons pourquoi et comment faire de l’éthique dans le domaine de la santé, et enfin nous verrons une étude de cas avec la covid-19
Cadrage de l’environnement de la E-Santé
L’émergence de la e-santé
L’usage du numérique dans le secteur médical, en somme : l’informatisation des tâches administratives et protocolaires a progressivement permis une meilleure organisation des données de chaque patient avec une accessibilité permanente, rapide et peu onéreuse à internet qui sera à l’origine de changements importants.
La santé est un secteur sous haute pression si l’on décrypte les données de l’OCDE en raison d’un vieillissement de la population qui augmente de plus en plus le taux de personnes sous traitement, des traitements qui aujourd’hui se renouvellent grâce à la data mais qui coûtent plus cher malheureusement dans un contexte où les Etats ont tendance à vouloir réduire leurs dépenses.

C’est dans ce contexte que l’on introduit le concept de la e-santé. En effet, la e-santé est une sphère très vaste qui englobe des activités, des pratiques médicales définis par des lois et réglementations, cela concerne également tout ce qui touche aux objets connectés pour la santé et le bien-être, les systèmes d’information des hôpitaux, la télé-surveillance (patient à domicile, prévention des chutes), des outils de formations à destination des professionnels. Le marché de la e-santé aujourd’hui pèse près de dix trilliards de dollars divisés en plusieurs parties avec un bon nombre de sous domaines très pointues et précis comme celui des assurances, des pharmacies, robots chirurgiens ou encore télémédecine.
Le marché de la e-santé est très lucratif, il pèse aujourd’hui près de dix trilliards de dollars.
C’est en raison de cette diversification si large qu’il est nécessaire de segmenter en catégories les différents champs qu’intègre la e-santé. Elle est née suite au besoin d’améliorer le suivi et la documentation de la santé des patients ainsi que leurs procédures avec par exemple les compagnies d’assurances. Si traditionnellement, les soignants se devaient de conserver des dossiers sous format papier des historiques et statuts de leurs patients, la hausse des coûts des soins de santé et progrès technologique ont permis l’émergence de nouveaux systèmes de suivi électroniques. La plupart des informations sont fournies par le biais d’une série d’objets numériques interactifs, entre autres, bon nombre d’appareils mobiles modernes sont conçus avec des capacités informatiques de renseignement personnel qui sont compatibles avec des applications téléchargeables qui permettent donc aux utilisateurs d’accéder de manière instantanée à des informations de santé.
Le mariage entre big data et santé
Étant une innovation majeure sans réelles antécédents, son impact s’effectue sur le tas et son établissement sur de plus en plus de domaines d’activités laisse entrevoir les changements qui vont apparaître dans le futur. Ainsi son usage progressivement globalisé signifie que les organismes commencent à réaliser l’importance d’une analyse optimale des données, en l’occurrence ici : des données de santé.
L’information est de nos jours un facteur clé pour de nombreux secteurs d’activités, plus les informations à disposition sont importantes et plus l’organisation s’établit de manière optimale afin d’obtenir de meilleurs résultats. Dans le secteur de la santé aujourd’hui, de nombreuses données dans des datacenters stockent des dossiers médicaux et hospitaliers, des résultats d’examens ou encore des recherches sur le biomédical.
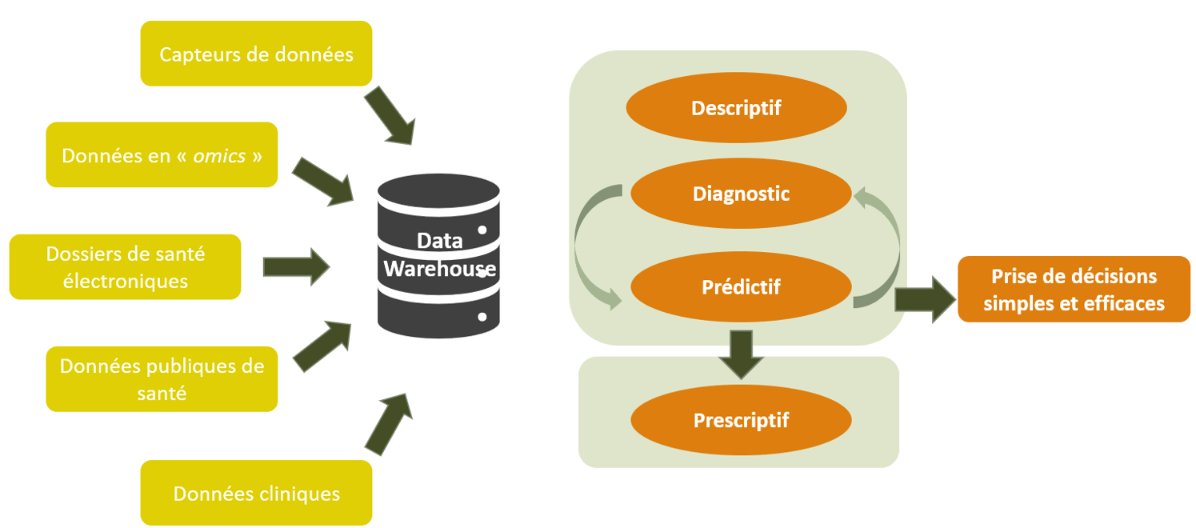
Les organisations de santé produisent des données à rythme très rapide qui soulèvent à la fois plusieurs défis et avantages. Avec l’apparition et l’évolution des systèmes informatiques, la numérisation des documentations et autres procédures, de nouveaux termes émergent tels que les logiciels de gestion de la pratique médicales, les dossiers de santé électroniques (DSE) ou les dossiers médicaux électroniques (DME) qui recueillent les données médicales et cliniques auprès des clients. Ces nouvelles entités de documentations ont collectivement le potentiel d’améliorer l’efficacité des services et les coûts des soins tout en réduisant les erreurs médicales. Ainsi l’utilisation et la gestion des données de santé dépendent de plus en plus des technologies de l’information.
Au sein de cette sphère, l’on verra progressivement s’établir diverses catégories d’acteurs dont les interactions et fonctions forment aujourd’hui un écosystème de la e-santé à la fois complexe et structuré de telle sorte à pouvoir servir aux intérêts de chacun d’eux.
L’écosystème des données de santé en France
Le projet Health Data Hub, une technologie nécessaire mais très controversée
En France, la question de la gestion des données de santé relève des différents registres et répond à deux fins distinctes. Tout d’abord nous avons une finalité scientifique, dans cette optique il s’agit de collecter et regrouper toutes les informations médicales des patients en France afin de créer une grande base de données que l’on pourra exploiter et traiter à des fins de recherche. Cette base de données va donc permettre de monter des projets de recherche pour améliorer la qualité des soins et traitements ainsi que d’enrichir les connaissances sur les diverses maladies. C’est dans cette logique qu’a été créé le très controversé Health Data Hub. Autour de ce sujet interagissent de nombreux acteurs qui cherchent à se faire entendre.
En premier plan nous avons la Commission Nationale de l’Information et des Libertés, la CNIL qui se préoccupe fortement des modalités de mise en place d’un projet de regroupement des données de santé des citoyens français. Dès la création officielle de la Plateforme des Données de Santé le 29 novembre 2019, la Cnil s’est tenue d’avertir des potentielles dérives et entraves aux libertés individuelles dû au caractère hautement sensible des informations collectées. Avec l’accélération du développement du projet HDH ces risques ont progressivement pris forme et la CNIL a cherché à empêcher le développement du projet dans sa forme actuelle en publiant un mémoire le 9 octobre 2020. Dans ce mémoire la commission exprime avant tout une préoccupation quant à l’hébergeur des données, celui-ci selon la CNIL doit impérativement être une entreprise européenne afin d’éviter tout transfert de données hors du continent.
Accompagnée par de nombreuses associations de médecins, la CNIL recourt à maintes reprises au conseil d’Etat qui malgré tout invalide sa demande de retirer la responsabilité d’hébergement du HDH à Microsoft via son cloud Azure. Bien que les différents représentants politiques, comme le ministre de la santé Olivier Véran, ont reconnu le risque d’hébergement des données par Microsoft, ils n’envisagent pas cependant de retirer la responsabilité à ce dernier d’aussi tôt. En effet, le changement d’hébergeur prendra deux ans selon le gouvernement. Le risque d’exploitation malintentionné continuera de peser encore longtemps sur nos données privées.
Le changement d’hébergeur prendra deux ans selon le gouvernement. Le risque d’exploitation malintentionné continuera de peser encore longtemps sur nos données privées.
Un autre acteur intervient également en scène, le collectif InterHop, une association regroupant des spécialistes en santé, des experts dans le digital et les systèmes d’information tous militants pour les logiciels libres et pour une utilisation autogérée des données de santé à l’échelle locale. Cette association publie le 15 décembre 2020 une tribune visant à attirer l’attention du gouvernement sur la vulnérabilité du système HDH. L’objectif de cette tribune est notamment de faire valoir l’intérêt des fournisseurs de service nationaux et européens et de montrer qu’ils sont aptes à assurer l’hébergement des données européennes.
C’est également l’idée autour de laquelle a été monté le projet du cloud européen et souverain, le projet GAIA-X. Ce projet a pour objectif de mettre fin à la vulnérabilité des entreprises européennes face à l’exploitation de leurs données sous la loi du Patriot/Cloud Act. Cependant malgré son ambition ce projet soulève lui aussi certains doutes. L’entreprise Palantir spécialisée dans la visualisation des données entre en partenariat avec le projet GAIA-X, ce qui suscite de nombreuses critiques car l’entreprise américaine est connue pour sa proximité avec la CIA. Il y a là une forte contradiction entre le principe central du projet et le choix des partenaires pour la réalisation de celui-ci, ce qui risque de fortement ternir l’image d’un projet pourtant prometteur.
Revenant à la polémique autour du HDH, le Groupe Open, chargé de développer ce projet, soutient l’idée que la plateforme de données de santé incarne l’ambition de la souveraineté numérique française et ne semble pas perturbé par le choix de l’hébergeur Microsoft et affirme que “l’écosystème numérique français s’est aussi construit avec des technologies d’entreprises internationales, à condition qu’elles se conforment à nos valeurs et accèdent aux obligations normatives, comme de ne pas avoir accès aux données stockées.”
Tout récemment Microsoft Azure a élaboré un nouveau service de cloud pour les données classées secret défense. Cette solution a été conçue sur mesure pour le gouvernement américain, preuves que quand il s’agit de la défense des intérêts nationaux la question de la sécurité prime avant tout.
Finalement le nécessaire besoin de renforcer la protection des données de santé au sein de la plateforme a été reconnu et le Secrétaire d’État chargé de la Transition numérique et des Communications électroniques, Cédric O a annoncé déjà chercher des alternatives à la solution Azure de Microsoft.
Mais pour autant le développement de la plateforme n’a pas été figé, en raison très certainement des besoin urgent de la gestion de la crise sanitaire (rappelons le, initialement le lancement du projet de données médicales centralisées sur une plateforme a été accéléré de trois mois en raison de la pandémie). Au début de ce mois la CNIL a autorisé six projets de recherche sur la base des données du HDH dont 3 portants sur la Covid-19.
Constatant l’hésitation gouvernementale aux revendications de l’opinion publique les acteurs français ont à leurs tours décidés de saisir l’opportunité. Il s’agit là de l’alliance d’Atos avec OVH Cloud pour former une solution multicloud 100% européenne. La solution se présente comme une plateforme à guichet unique proposant une multitude d’offres regroupées selon les besoins des clients.
Les deux entreprises font déjà partie du projet Gaia-X et contribuent à la constitution des standards communs de cloud computing. OVH Cloud vient tout récemment d’obtenir la certification d’hébergeur de données le « SecNumCloud » pour sa solution de cloud privé « Hosted Private Cloud » délivrée par l’Agence nationale de sécurité des systèmes d’information (ANSSI). Avec cette certification le groupe peut à présent prétendre à la place de Microsoft dans le projet HDH, car en effet le portefeuille de label de sécurité et de souveraineté lui permet de répondre aux besoins divers et variés des organisations publiques et privées.
Les deux entreprises françaises entendent bien donner du fil à retordre aux géants californiens de la tech en répondant à un réel besoin de contrôle sécurisé des données privées. Cette alliance stratégique représente l’espoir du cloud souverain européen car l’objectif est d’assurer l’infrastructure la plus respectueuses possible des données et ceux en unissant leurs infrastructures (130 datacenters à travers le monde).
Orange Healthcare et Enovacom
Outre les fins scientifiques et de recherche, les données de santé sont aussi générées et forment des flux dans une logique opérationnel comme dans le cas d’envoi de bilans de santé, prise de rendez-vous et autres informations médicales.
Dans le domaine de la e-santé et du stockage des données gravitent aussi de tels acteurs nationaux comme le service de santé de Orange Business, Orange Health Care. Depuis le premier octobre 2020 Enovacom, une entreprise marseillaise est chargée de regrouper et développer les offres de Orange dans le domaine de la santé. C’est ainsi que, certifié HDS (Hébergeur de Données de Santé) Orange Healthcare a conclu avec la French Tech de l’IoT, Bewelle Connect un contrat pour héberger ses données générées par les objets connectés.
Une plateforme de prise de rendez-vous médicaux qui a le vent en poupe, Doctolib
Un autre acteur important de l’écosystème est ayant accru sa notoriété durant la pandémie est le service de prise de rendez-vous médicaux Doctolib. Selon cette plateforme “Pendant le confinement, le nombre de téléconsultations a été multiplié par 100. Aujourd’hui encore, il resterait 30 fois plus élevé qu’avant la crise du coronavirus.” Cet accroissement de l’utilisation a attiré l’attrait de l’entreprise notamment de la part des hackers qui lui ont volé le 23 juillet 6000 données de prises de rdv. L’enjeu de protection et de confidentialité devient donc crucial et la pépite française a entrepris de renforcer les mesures de sécurité, elle a fait tout récemment appel à l’entreprise Tanker pour assurer le plus haut niveau de cryptage de ses données. Cependant là aussi revient la question de l’hébergement de ses informations. Bien qu’impératif, selon la réglementation du RGPD, Doctolib ne souhaite pas divulguer le nom de son ou ses hébergeurs. Selon certains experts l’hébergeur serait Amazon avec sa solution Amazon Web Service.
Comme nous l’avons vu, l’univers du Big Data en santé est complexe, les acteurs sont très nombreux et ceux présentés ultérieurement ne forment pas une liste exhaustive. Le domaine de la gestion des données de santé (toujours plus nombreuses) comprend de multiples problématiques touchant aux sphères de la jurisprudence (avec la protection des données personnelles et les libertés individuelles), de la cybersécurité (avec les problématiques de fuite et de vol de données, ou encore de leur transfert à des entités tiers). Mais il convient de ne pas oublier l’aspect éthique de la question également car en effet les informations sur les patients font objet de secret médical. La question se pose alors : comment exploiter et traiter les données de santé pour en tirer une utilité maximum tout en garantissant une manipulation éthique de celles-ci.
Quel lien entre éthique, big data et e-santé ?
Les limites des technologies du Big Data
Les technologies du Big data sont extrêmement utiles et, à travers leur fonctionnement, offrent la possibilité d’octroyer des services personnalisés. Ces services personnalisés sont basés sur des modèles capables de prédire un bon nombre d’évènements et de comportements, en fonction des données qui nourrissent l’algorithme avec lequel elles fonctionnent. L’influence des technologies du Big Data s’étend à bon nombre de secteurs. Toutefois la nouveauté et la rapidité à laquelle se propage cette technologie pose différents types de challenges aux différents secteurs impliqués. Notamment dans le secteur médical, qui vise à utiliser ces technologies pour la médecine personnalisée/de précision grâce à la médecine prédictive.
Le conflit entre potentiel et réalité
Les promesses diffusées par les promoteurs des technologies du big data doivent être remises au goût du jour afin d’éviter des désastres futurs. Certaines de ces promesses sont le développement rapide de la médecine personnalisée, et des diagnostics automatisé basé sur les données massives récolté. Les modèles qu’on nous présente aujourd’hui ou qui sont promulgués ne passent pas nécessairement par les tests et les étapes nécessaires. Les études derrière ces technologies, afin de prouver leur efficacité, seraient trop laxistes pour la plupart.
Certains modèles ne seraient pas testés dans des environnements variés, ce qui n’est pas réaliste par rapport à ce qui peut être demandé par un médecin en clinique. De plus, une fois confrontées à des situations inconnues, ces machines doivent repasser par une phase d’apprentissage, à l’instar de l’algorithme de Google déployé en Thaïlande afin de repérer la rétinopathie diabétique via des images rétine, lorsqu’il a rencontré des difficultés à effectuer sa tâche correctement une fois que la luminosité était faible.

La promesse de médecine personnalisée est aujourd’hui, et sera peut-être pour toujours impossible à réaliser. En effet les technologies du Big Data tel qu’on les connaît sont trop limitées et n’apportent pas, contrairement à ce qui est répandu, une solution infaillible. Celle-ci est limitée dans plusieurs aspects.
Premièrement l’impossibilité pour les modèles de faire une distinction entre cause et effet par la simple observation de données. L’inférence causale est une grande partie de la médecine mais reste hors de portée de la machine. L’inférence causale nécessite de faire des suppositions, alors que les algorithmes sont tous programmés pour faire des prédictions, c’est-à-dire, arriver au résultat le plus plausible à travers les données statistiques récoltées.
Une autre limitation est que la complexité des états de santé ne peut être comprise que par la probabilité. Les probabilités ne permettent pas d’avoir des certitudes, et n’arrivent qu’au mieux à réduire le doute a un petit groupe de possibilités et non à un unique individu. Par exemple, si on lance deux dés, on connaît la valeur la plus probable (sept) et on connaît à 100% la probabilité des autres possibilités, cependant, tout cela ne nous révèle rien sur le résultat du prochain lancé. Dans ce cas, la médecine personnalisée (de précision) est impossible, même dans le cas où les modèles arrivent un jour à faire de l’inférence causale.
Une mise en œuvre massive de ces technologies sans en comprendre les rouages, limitations et autres, pourrait causer des désastres pour certains patients. Intégrer l’éthique dans les technologies du Big data et leurs utilisations serait un moyen de ralentir les ambitions des différentes parties afin d’avoir les meilleurs modèles possibles. Ce qui n’auront pas pour but le remplacement des médecins, ni des performances surréalistes, qui mettent potentiellement en péril la vie des patients, mais des technologies visant à l’amélioration des soins et l’assistance au médecin.
Le manque de régulation sur les technologies du Big Data : l’exemple du Health Data Hub
De plus, les règles qui régissent le big data sont loin d’être exhaustives et ce manque de rigueur amène des problèmes éthiques qui sont des dilemmes pour les utilisateurs. Avec l’intensification de l’utilisation de ces outils dans le secteur médical, beaucoup de droits inhérents à ce service se voient bafoués. Même si ces technologies sont extrêmement utiles pour la surveillance des variations de l’état des malades, elles restent toutefois sensibles et ne devraient jamais être à la disposition de personnes mal intentionnées. Rythme cardiaque, température, taux de cholestérol, grâce au Big Data, toutes ces données peuvent être collectées et étudiées de manière quasi immédiatement permettant notamment des interventions d’urgence.
Les données de santé sont probablement, parmi toutes les autres données qualifiées de « nouveau pétrole », les plus sensibles et donc lucratives pour ceux qui les convoitent. Leur sécurité devrait donc être la priorité numéro 1 des décideurs.
Malheureusement, elles sont souvent hébergées par des acteurs ne respectant pas les droits fondamentaux des patients. Le droit au consentement à l’utilisation des données par exemple, n’est pas toujours demandé. Plusieurs plateformes fonctionnent sous le principe de consentement présumé. Ce principe implique que tout utilisateur, dès lors qu’il s’inscrit sur la plateforme concernée, est présumé donner son accord sur l’utilisation de ses données. Le seul moyen de se défaire de ce consentement présumé, est de lancer des démarches, souvent ardues et pénibles.
De plus, les options qui permettent de prendre connaissance de la manière dont sont utilisées nos données sont souvent rédigées de manière à dissuader la lecture. Ces restrictions forcent les utilisateurs qui ne veulent pas partager leurs données à, soit chercher des alternatives, la plupart du temps peu appropriées, ou à faire face à un manque d’alternatives. Dans ce cas l’option de consentement n’est plus une option mais une obligation. Ce processus fait en sorte que l’on est au final obligé d’accepter au moins une certaine exploitation par manque d’alternative.
Ce problème est encore plus prononcé dans le secteur de la santé où la valeur de ces données surpasse celle des autres. En effet, en connaissant l’état de santé d’un individu, on peut en déduire beaucoup sur ses envies. Les entreprises sont donc friandes de ce genre de données et des opportunités de se les octroyer. De plus, les États n’étant pas toujours bien informés sur le sujet sont susceptibles de prendre des décisions mettant en péril la sécurité des données de leurs citoyens. Un exemple qui reflète parfaitement ce dilemme est justement l’instauration du Health Data Hub en France.

Le Health Data Hub (HDH) est une initiative de l’État français. Il s’agit d’une plateforme sur laquelle sera récolté et rassemblé toutes les données de santé des Français. Les données sont stockées de manière anonymisée/pseudonymes. Ces données sont mises au service de la recherche afin d’en sortir des tendances, par exemple de quoi les Français souffrent majoritairement. Cela permettrait aussi des avancées considérables en terme scientifique. Les personnes ayant accès à cette plateforme sont théoriquement restreint aux professionnels de santé et aux chercheurs.
Mais il est possible de déroger à cette règle et d’avoir l’accès aux données sous la condition de l’intérêt public. C’est là que l’on rencontre l’une des critiques majeures du HDH. L’intérêt général est une notion extrêmement vague et difficile à bien définir. Sous la condition de l’intérêt général, n’importe qui peut avoir accès aux informations des français, du moment qu’ils arrivent à prouver que leur cause répond celui-ci. Par exemple, des entreprises, ou des assureurs qui réussissent à avoir accès à ces informations, pourront les utiliser à des fins purement économiques.
Par exemple, elles seraient utiles pour le lancement d’opérations marketing basées sur les données qu’ils avaient pu récupérer lors de leurs accès. Il s’agit ici d’une violation indirecte de la vie privée (les données étant anonymes). De plus, l’anonymat, avec les technologies de nos jours, n’est plus une garantie de sécurité. Il devient en effet tous les jours plus facile de tracer et récupérer l’identité des individus.
La souveraineté numérique et le consentement remis en question
Un autre point de contention est le lieu de stockage des données. Comme nous l’avons vu, le HDH est logé sur Microsoft Azure. Il s’agit ici d’une plateforme appartenant à Microsoft, une entreprise américaine, et une des GAFAM, qui sont connues pour leurs capacités à collecter les données de leurs utilisateurs. De ce fait, le problème d’extraterritorialité des lois américaines entre en jeu, et fait face à la souveraineté numérique de la France. L’Etat français ayant déjà fait les frais de l’extraterritorialité américaine plusieurs fois, lors de l’affaire Alstom par exemple, devrait se tenir sur leur garde.
Ici, la France risque de perdre le contrôle des données de ses citoyens au profit des Etats-Unis. En effet, les données, logées sur une plateforme d’origine américaine, sont susceptibles d’être rapatriées au pays. Cette clause fait partie du Cloud Act que l’ancien Président Donald Trump a signé en 2018.
La France risque de perdre le contrôle des données de ses citoyens au profit des Etats-Unis à cause du Cloud Act.
Dernièrement, le HDH fonctionne sous le principe de consentement présumé. Ceci est un autre des points gênant du HDH car même les personnes ne voulant pas y participer pourraient se retrouver par mes gardes dans la base de données et potentiellement voir leur donnée transférée et exploitée par les Etats-Unis. Même si la Cnil dénonce et sonne la sonnette d’alarme, et que ce genre de mesure est en violation avec le RGPD, on constate une certaine passivité au niveau de l’État, ce qui en plus d’une communication très faible sur le sujet, n’inspire pas confiance sur les raisons de l’installation d’une telle plateforme.
Ce manque de rigueur dans l’établissement de règles claires et strictes autour du sujet, est un signe de laxisme excessif de nos institutions. La question d’éthique n’est pas prise au sérieux, cependant, c’est une question à laquelle il faudra répondre tôt ou tard. L’établissement ne serait-ce que d’une simple charte permettra potentiellement d’éviter de nombreux problèmes futurs liés à ce sujet.
Plus globalement, la vitesse à laquelle se développent et se propagent les technologies dépasse largement les capacités cognitives des utilisateurs. Ceux- ci se sentent de plus en plus emportés dans le tourbillon de l’innovation et du progrès sans avoir le temps de se poser les questions fondamentales : celles de leurs « privacy », de leur liberté de disposer de soi-même et de leurs informations confidentielles. Les exemples où les utilisateurs se retrouvent dépossédés de leurs identités numériques sont nombreux, et le projet du Health Data Hub peut potentiellement se retrouver parmi le rang de ceux-ci si les autorités ne prennent pas une véritable conscience et ne réalisent pas l’ampleur des dégâts. Il faut à tout prix éviter de devenir une colonie numérique d’extraction de données de la Silicon Valley. Pour autant le gouvernement semble avoir tranché sur le sujet. D’ici deux ans, délai annoncé par le ministre du numérique pour changer d’hébergeur, peuvent survenir de nombreux incidents.
Par Oluwafisayomi AGUNBIADE Ayman HILAL et Alina IBRAGIMOVA, étudiants en master 2 intelligence économique et stratégies compétitives à l’université d’Angers
Sources et Bibliographie
- Le Figaro « Microsoft ne doit plus gérer les données de santé des Français, alerte la Cnil »
- « Time to reality check the promises of machine learning-powered precision medicine », The Lancet Digital Health, Jack Wilkinson, Kellyn F Arnold, Eleanor J Murray, Maarten van Smeden, Kareem Carr, Rachel Sipy, 16 septembre 2020
- «Big data and the emerging ethical challenges » Mohammed Saqr, septembre-octobre 2017
- « Health Data Hub : le sombre diagnostic du Dr CNIL » Marc Rees,Next Impact, 4 novembre 2020
- « La Cnil autorise trois projets “Covid-19” accompagnés par le Health Data Hub », Wassinia Zirar, Tecpharma, 8 décembre 2020
- « Palantir rejoint le projet Gaia-X, un ralliement qui interroge», Benjamin Terrasson, Siècle digital, 27 décembre 2020
- « Marcel Goldberg et Marie Zins La plate-forme « Health Data Hub » pose des questions de sécurité majeures », Le Monde, 30 octobre 2020
- « Le Conseil d’Etat laisse Microsoft aux manettes de Health Data Hub, mais alerte d’un risque », Anais Cherif, La Tribune, 16 octobre.
- « Opinion | Le Health Data Hub, un outil à la pointe de l’innovation numérique publique », LesEcho.fr, 5 juin 2020
- Site de l’association IntersHop
- Orange Business Services accélère dans la e-santé et regroupe ses activités Santé au sein de sa filiale Enovacom
- Retour d’expérience : Enovacom héberge les données de santé de BewellConnect dans ses datacenters certifiés HDS(Communiqué)
- Atos et OVHcloud s’allient pour lancer une solution multi-cloud européenne